Inventory Management with Attention-Based Meta Actions
Keisuke Izumiya, Edgar Simo-Serra
Roguelike games are a challenging environment for Reinforcement Learning (RL) algorithms due to having to restart the game from the beginning when losing, randomized procedural generation, and proper use of in-game items being essential to success. While recent research has proposed roguelike environments for RL algorithms and proposed models to handle this challenging task, to the best of our knowledge, none have dealt with the elephant in the room, i.e., handling of items. Items play a fundamental role in roguelikes and are acquired during gameplay. However, being an unordered set with a non-fixed amount of elements which form part of the action space, it is not straightforward to incorporate them into an RL framework. In this work, we tackle the issue of having unordered sets be part of the action space and propose an attention-based mechanism that can select and deal with item-based actions. We also propose a model that can handle complex actions and items through a meta action framework and evaluate them on the challenging game of NetHack. Experimental results show that our approach is able to significantly outperform existing approaches.
Model
Action recursion and item feature extractor are incorporated into the existing model, shown above the dashed line.
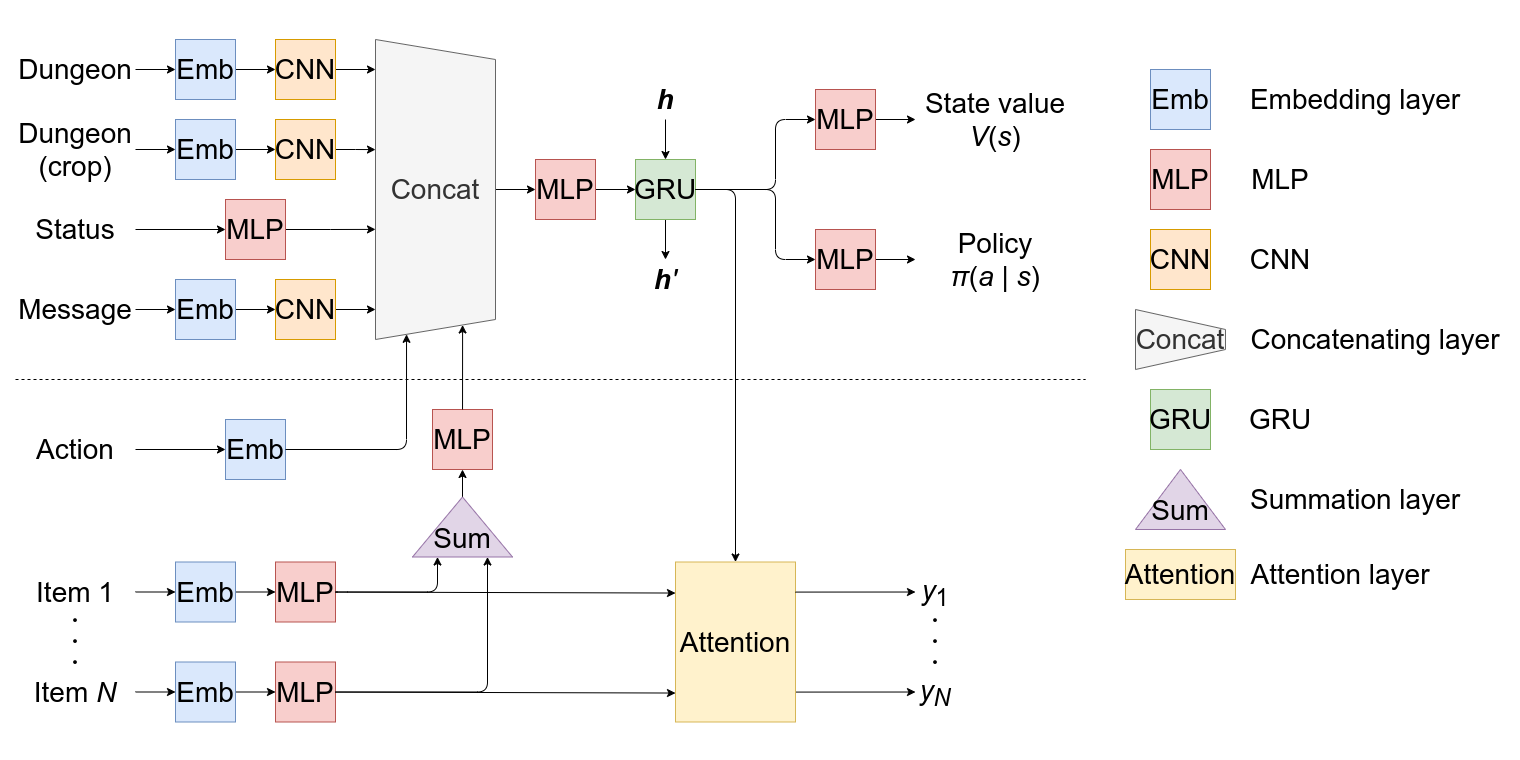
Action Recursion
The embedding layer is added to the model to incorporate the previous action into the representation of the current state.
Inventory Feature Extraction
After computing the features of each item in the inventory $\bm{x}_i$, the feature of all items $\bm{x}$ is computed as $\bm{x}=\mathrm{MLP}\left(\sum_i\bm{x}_i\right)$ using summation, an unordered operation.
Items' Score Calculation
The score of each item is calculated with the attention mechanism. Specifically, using matrices $\bm{W}_{\mathrm{Q}}, \bm{W}_{\mathrm{K}}$ and vector $\bm{w}_{\mathrm{V}}$, the score of the $i$th item is calculated by
[[ y_i=\frac{\bm{q}^{\top}\bm{k}_i}{\sqrt{d_k}}\,v_i, ]]
where
[[ \begin{aligned}
\bm{q} &= \bm{W}_{\mathrm{Q}}\bm{f}, \\
\bm{k}_i &= \bm{W}_{\mathrm{K}}\bm{x}_i, \\
v_i &= \bm{w}_{\mathrm{V}}^{\top}\bm{x}_i,
\end{aligned} ]]
$d_k$ is the dimension of $\bm{q}$ and $\bm{k}_i$, and $\bm{f}$ is the representation of the current state; the output of the GRU.
Result
Errata (Paper)
| Page | Location | Error | Correction |
|---|---|---|---|
| 5 | Second line in Eq. (9) | [[ {}+\lambda\pi_{\mathrm{v}}(b_0\mid S_t)\nabla\sum_{b\in\mathcal{A}_{\mathrm{i}}}-\pi_{\mathrm{i}}(b\mid S_t)\log\pi_{\mathrm{i}}(b\mid S_t) ]] | [[ {}+\lambda\nabla\pi_{\mathrm{v}}(b_0\mid S_t)\sum_{b\in\mathcal{A}_{\mathrm{i}}}-\pi_{\mathrm{i}}(b\mid S_t)\log\pi_{\mathrm{i}}(b\mid S_t) ]] |
Paper
Keisuke Izumiya and Edgar Simo-Serra, Inventory Management with Attention-Based Meta Actions, IEEE Conference on Games (CoG), 2021.