Spotlight Video
Approach
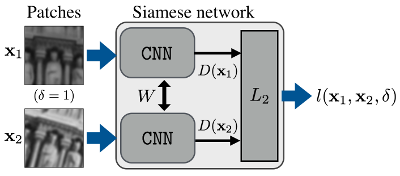
Our approach consists in training a Convolutional Neural Network (CNN) to build a feature representation of an image patch. We train by using two patches simultaneously that should either correspond to the same point and thus have similar features, or different points and thus different features. We optimize this by using a Siamese architecture, that is, we input two patches simultaneous and minimize the L2 distance between the features if they correspond to the same point and maximize the L2 distance if they correspond to different points. In order to learn efficient and discriminative representations, we propose a positive and negative mining approach which is shown to be critical for performance.
Results
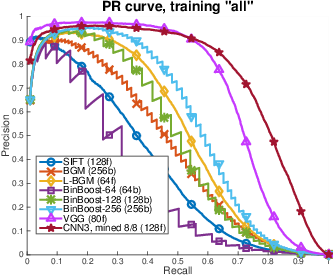 We train and evaluate our results on the
Brown dataset1. We also provide evaluation on other datasets including the
DaLI dataset and show we significantly outperform existing
approaches. Furthermore, our approach computes 128 dimension vectors that can be
compared directly with L2 and thus is suitable as a drop-in replacement
for SIFT.
We train and evaluate our results on the
Brown dataset1. We also provide evaluation on other datasets including the
DaLI dataset and show we significantly outperform existing
approaches. Furthermore, our approach computes 128 dimension vectors that can be
compared directly with L2 and thus is suitable as a drop-in replacement
for SIFT.
| Dataset Split | SIFT | BGM | L-BGM | BinBoost256 | VGG | Ours |
|---|---|---|---|---|---|---|
| ND | 0.349 | 0.487 | 0.495 | 0.549 | 0.663 | 0.667 |
| YO | 0.425 | 0.495 | 0.517 | 0.533 | 0.709 | 0.545 |
| LY | 0.226 | 0.268 | 0.355 | 0.410 | 0.558 | 0.608 |
| All | 0.370 | 0.440 | 0.508 | 0.550 | 0.693 | 0.756 |
For full details and results please refer to the full paper.