研究紹介
-
Smart Inker: ラフスケッチのペン入れ支援

本研究では、深層学習を応用して対話的にラフスケッチのペン入れができるツール、スマートインカー(Smart Inker)を提案する。 スマートインカーは、途切れた線を自然につなぎ、不要な線を効率的に消すことが可能な“スマート”ツール機能をもち、自動出力された線画を効果的に修正することができる。 このような機能を実現するため、本手法ではデータ駆動型のアプローチを取る。スマートインカーは全層畳み込みニューラルネットワークにもとづいており、 このネットワークはユーザ編集とラフスケッチ両方を入力とし正確な線画を出力できるように学習させている。 これにより、様々な種類の複雑なラフスケッチに対して高精度かつリアルタイムの編集が可能となる。 これらのツールの学習のため、提案手法では2つの重要な技術を考案する。すなわち、ユーザ編集をシミュレーションして学習データを作成するデータ拡張手法、 および線画のベクタデータにより学習した細線化ネットワークを用いた線画標準化手法である。これらの手法とスケッチに特化したデータ拡張を組み合わせることで、 実際のユーザ編集データを用意することなく様々な編集パターンを含む学習データを大量に作成でき、効果的にそれぞれのネットワークを学習させることができる。 実際に提案ツールを用いてラフスケッチにペン入れをするユーザテストを行った結果、商用のイラスト制作ソフトに比べ提案ツールは簡単かつ短時間で線画作成が可能となり、 イラスト作成経験がほとんどないユーザでもきれいな線画を作成できることが確かめられた。
Deep Sketch Vectorization via Implicit Surface ExtractionChuan Yan, Yong Li, Deepali Aneja, Matthew Fisher, Edgar Simo-Serra, Yotam GingoldACM Transactions on Graphics (SIGGRAPH), 2024Real-Time Data-Driven Interactive Rough Sketch InkingEdgar Simo-Serra, Satoshi Iizuka, Hiroshi IshikawaACM Transactions on Graphics (SIGGRAPH), 2018 -
敵対的データ拡張による自動線画化
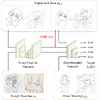
本研究では、ラフスケッチの自動線画化を効果的に学習するための統合的なフレームワークを提案する。提案手法では、線画化ネットワークおよび線画識別ネットワークを構築し、線画識別ネットワークは本物の線画と線画化ネットワークによって作られた線画を区別するように、線画化ネットワークは出力した線画を識別ネットワークが区別できないように学習を行う。このアプローチには2つの利点がある。一つ目は、識別ネットワークは線画の「構造」を学習できるため、線画化ネットワークがより精細で本物に近い線画を出力できるようになる。二つ目は、対応関係のないラフスケッチと線画を学習に取り入れることができ、実世界の多様な教師なしデータを線画化ネットワークに学習させることができる点である。本学習フレームワークを用いることで、最新の線画化手法よりも精細で多様な線画化が可能となる。さらに、提案手法は入力画像のみをさらに学習することで、入力画像に対する線画化ネットワークの最適化を行うことができる。また、提案手法により、逆問題、すなわち線画から鉛筆画への変換も学習できることを示す。
Mastering Sketching: Adversarial Augmentation for Structured PredictionEdgar Simo-Serra*, Satoshi Iizuka*, Hiroshi Ishikawa (* equal contribution)ACM Transactions on Graphics (Presented at SIGGRAPH), 2018 -
シーンの大域的かつ局所的な整合性を考慮した画像補完

本研究では,畳み込みニューラルネットワークを用いて,シーンの大域的かつ局所的な整合性を考慮した画像補完を行う手法を提案する。提案する補完ネットワークは全層が畳み込み層で構成され,任意のサイズの画像における自由な形状の「穴」を補完できる。この補完ネットワークに,シーンの整合性を考慮した画像補完を学習させるため,本物の画像と補完された画像を識別するための大域識別ネットワークと局所識別ネットワークを構築する。大域識別ネットワークは画像全体が自然な画像になっているかを評価し,局所識別ネットワークは補完領域周辺のより詳細な整合性によって画像を評価する。この2つの識別ネットワーク両方を「だます」ように補完ネットワークを学習させることで,シーン全体で整合性が取れており,かつ局所的にも自然な補完画像を出力することができる。提案手法により,様々なシーンにおいて自然な画像補完が可能となり,さらに従来のパッチベースの手法ではできなかった,入力画像に写っていないテクスチャや物体を新たに生成することもできる。これにより,人間の顔の一部を補完するような,複雑な画像補完を実現した。
Globally and Locally Consistent Image CompletionSatoshi Iizuka, Edgar Simo-Serra, Hiroshi IshikawaACM Transactions on Graphics (SIGGRAPH), 2017 -
ラフスケッチの自動線画化

本研究では、畳込みニューラルネットワークを用いてラフスケッチを線画に自動変換する手法を提案する。既存のスケッチ簡略化手法の多くは単純なラフスケッチのベクター画像のみを対象としており、スキャンした鉛筆画など、ラスター形式の複雑なラフスケッチを線画化するのは困難であった。これに対し提案手法では、3種類の畳込み層から構成されるニューラルネットワークモデルによって複雑なラフと線画の対応を学習することで、ラスター形式の様々なラフスケッチを良好に線画化することができる。提案モデルでは、任意のサイズやアスペクト比をもつ画像を入力として扱うことが可能であり、出力される線画は入力画像と同じサイズになる。また、このような多層構造をもつモデルを学習させるため、ラフスケッチと線画がペアになった新しいデータセットを構築し、モデルを効果的に学習させる方法を提案した。得られた結果についてユーザテストを行い、提案手法の性能が既存手法を大きく超えることを確認した。
Learning to Simplify: Fully Convolutional Networks for Rough Sketch CleanupEdgar Simo-Serra*, Satoshi Iizuka*, Kazuma Sasaki, Hiroshi Ishikawa (* equal contribution)ACM Transactions on Graphics (SIGGRAPH), 2016 -
白黒画像の全自動色付け

本研究では、ディープネットワークを用いて白黒画像をカラー画像に自動変換する手法を提案する。提案手法では、画像の大域特徴と局所特徴を考慮した新たな畳込みネットワークモデルを用いることで、画像全体の構造を考慮した自然な色付けを行うことができる。提案モデルにおいて、大域特徴は画像全体から抽出され、局所特徴はより小さな画像領域から計算される。これらの特徴は“結合レイヤ”によって一つに統合され、色付けネットワークに入力される。このモデル構造は入力画像のサイズが固定されず、どんなサイズの画像でも入力として用いることができる。また、モデルの学習のために既存の大規模な画像分類のデータセットを利用し、それぞれの画像の色とラベルを同時に学習に用いることで、効果的に大域特徴を学習できるようにしている。提案手法により、100年前の白黒写真など、様々な画像において自然な色付けを実現できる。色付けの結果はユーザテストによって評価し、約90%の色付け結果が自然であるという回答が得られた。
Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous ClassificationSatoshi Iizuka*, Edgar Simo-Serra*, Hiroshi Ishikawa (* equal contribution)ACM Transactions on Graphics (SIGGRAPH), 2016 -
ランキングロスと分類ロスにもとづくファッションデータの特徴抽出

多様なファッション画像を効果的に分類できる特徴量抽出手法を提案する。 提案手法では、ランキングロスとクロスエントロピーロスを合わせて畳込みニューラルネットワークを学習させることで、 ノイズが多く含まれるようなデータセットに対しても良好に特徴抽出が行えることを示した。
Fashion Style in 128 Floats: Joint Ranking and Classification using Weak Data for Feature ExtractionEdgar Simo-Serra and Hiroshi IshikawaConference in Computer Vision and Pattern Recognition (CVPR), 2016 -
Siameseネットワークモデルを用いた画像特徴量抽出

Siameseネットワークモデルを効率的に学習させることで、 ロバストな画像特徴量を計算する手法を提案する。 提案手法では、モデルに2つの画像パッチを入力し、出力された特徴量の誤差によってモデルを学習させる。 また、入力するパッチをその識別の難しさによって分類し、識別が困難なパッチを優先的に学習させることで、SIFT特徴量よりもロバストな特徴量の抽出を実現した。
Discriminative Learning of Deep Convolutional Feature Point DescriptorsEdgar Simo-Serra*, Eduard Trulls*, Luis Ferraz, Iasonas Kokkinos, Pascal Fua, Francesc Moreno-Noguer (* equal contribution)International Conference on Computer Vision (ICCV), 2015 -
ファッション性の推定
Being able to understand and model fashion can have a great impact in everyday life. From choosing your outfit in the morning to picking your best picture for your social network profile, we make fashion decisions on a daily basis that can have impact on our lives. As not everyone has access to a fashion expert to give advice on the current trends and what picture looks best, we have been working on developing systems that are able to automatically learn about fashion and provide useful recommendations to users. In this work we focus on building models that are able to discover and understand fashion. For this purpose we have created the Fashion144k dataset, consisting of 144,169 user posts with images and their associated metadata. We exploit the votes given to each post by different users to obtain measure of fashionability, that is, how fashionable the user and their outfit is in the image. We propose the challenging task of identifying the fashionability of the posts and present an approach that by combining many different sources of information, is not only able to predict fashionability, but it is also able to give fashion advice to the users.
Neuroaesthetics in Fashion: Modeling the Perception of FashionabilityEdgar Simo-Serra, Sanja Fidler, Francesc Moreno-Noguer, Raquel UrtasunConference in Computer Vision and Pattern Recognition (CVPR), 2015 -
単眼画像の人間の三次元位置の推定

This line of research focuses on the estimation of the 3D pose of humans from single monocular images. This is an extremely difficult problem due to the large number of ambiguities that rise from the projection of 3D objects to the image plane. We consider image evidence derived from the usage of different detectors for the different parts of the body, which results in noisy 2D estimations where the estimation uncertainty must be compensation. In order to deal with these issues, we propose different approaches using discriminative and generative models to enforce learnt anthropomorphism constraints. We show that by exploiting prior knowledge of human kinematics it is possible to overcome these ambiguities and obtain good pose estimation performance.
ProjFlow: Projection Sampling with Flow Matching for Zero‑Shot Exact Spatial Motion ControlAkihisa Watanabe, Qing Yu, Edgar Simo-Serra, Kent FujiwaraConference in Computer Vision and Pattern Recognition (CVPR), 2026A Joint Model for 2D and 3D Pose Estimation from a Single ImageEdgar Simo-Serra, Ariadna Quattoni, Carme Torras, Francesc Moreno-NoguerConference in Computer Vision and Pattern Recognition (CVPR), 2013Single Image 3D Human Pose Estimation from Noisy ObservationsEdgar Simo-Serra, Arnau Ramisa, Guillem Alenyà, Carme Torras, Francesc Moreno-NoguerConference in Computer Vision and Pattern Recognition (CVPR), 2012 -
測地混合モデル

There are many cases in which data is found to be distributed on a Riemannian manifold. In these cases, Euclidean metrics are not applicable and one needs to resort to geodesic distances consistent with the manifold geometry. For this purpose, we draw inspiration on a variant of the expectation-maximization algorithm, that uses a minimum message length criterion to automatically estimate the optimal number of components from multivariate data lying on an Euclidean space. In order to use this approach on Riemannian manifolds, we propose a formulation in which each component is defined on a different tangent space, thus avoiding the problems associated with the loss of accuracy produced when linearizing the manifold with a single tangent space. Our approach can be applied to any type of manifold for which it is possible to estimate its tangent space.
3D Human Pose Tracking Priors using Geodesic Mixture ModelsEdgar Simo-Serra, Carme Torras, Francesc Moreno-NoguerInternational Journal of Computer Vision (IJCV) 122(2):388-408, 2016Lie Algebra-Based Kinematic Prior for 3D Human Pose TrackingEdgar Simo-Serra, Carme Torras, Francesc Moreno-NoguerInternational Conference on Machine Vision Applications (MVA) [best paper], 2015Geodesic Finite Mixture ModelsEdgar Simo-Serra, Carme Torras, Francesc Moreno-NoguerBritish Machine Vision Conference (BMVC), 2014 -
変形・照明不変の特徴量

DaLI descriptors are local image patch representations that have been shown to be robust to deformation and strong illumination changes. These descriptors are constructed by treating the image patch as a 3D surface and then simulating the diffusion of heat along the surface for different intervals of time. Small time intervals represent local deformation properties while large time intervals represent global deformation properties. Additionally, by performing a logarithmic sampling and then a Fast Fourier Transform, it is possible to obtain robustness against non-linear illumination changes. We have created the first feature point dataset that focuses on deformation and illumination changes of real world objects in order to perform evaluation, where we show the DaLI descriptors outperform all the widely used descriptors.
DaLI: Deformation and Light Invariant DescriptorEdgar Simo-Serra, Carme Torras, Francesc Moreno-NoguerInternational Journal of Computer Vision (IJCV) 115(2):135-154, 2015Deformation and Illumination Invariant Feature Point DescriptorFrancesc Moreno-NoguerConference in Computer Vision and Pattern Recognition (CVPR), 2011 -
衣服の領域分割

In this research we focus on the semantic segmentation of clothings from still images. This is a very complex task due to the large number of classes where intra-class variability can be larger than inter-class variability. We propose a Conditional Random Field (CRF) model that is able to leverage many different image features to obtain state-of-the-art performance on the challenging Fashionista dataset.
A High Performance CRF Model for Clothes ParsingEdgar Simo-Serra, Sanja Fidler, Francesc Moreno-Noguer, Raquel UrtasunAsian Conference on Computer Vision (ACCV), 2014 -
木構造のキネマティック合成

Kinematic synthesis consists of the theoretical design of robots to comply with a given task. In this project we focus on finite point kinematic synthesis, that is, given a specific robotic topology and a task defined by spatial positions, we design a robot with that topology that complies with the task.
Tree topologies consist of loop-free structures where there can be many end-effectors. A characteristic of these topologies is that there are many shared joints. This allows some structures that may seem redundant to not actually be redundant when considering all the end-effectors at once. The main focus of this work is the design of grippers that have topologies similar to that of the human hand, which can be seen as a tree topology.
Kinematic Synthesis using Tree TopologiesEdgar Simo-Serra, Alba Perez-GraciaMechanism and Machine Theory (MAMT) 72:94-113, 2014Kinematic Synthesis of Multi-Fingered Robotic Hands for Finite and Infinitesimal TasksEdgar Simo-Serra, Alba Perez-Gracia, Hyosang Moon, Nina RobsonAdvances in Robot Kinematics (ARK), 2012Design of Non-Anthropomorphic Robotic Hands for Anthropomorphic TasksEdgar Simo-Serra, Francesc Moreno-Noguer, Alba Perez-GraciaASME International Design Engineering Technical Conferences (IDETC), 2011Kinematic Model of the Hand using Computer VisionEdgar Simo-SerraDegree Thesis, 2011