
For related work, see our work on parsing clothing in images and predicting fashionability.
Method
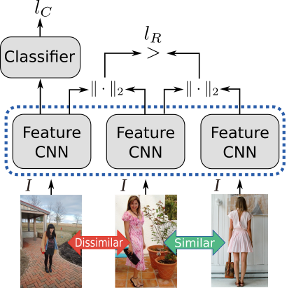
We base our approach on combining both a classification network with a feature network that are learnt jointly with a ranking and classification loss. We do this by first defining a similarity metric on the user provided noisy tags. Using this metric we can then roughly determine semantically similar and dissimilar images. Given an anchor or reference image, we then form triplets of images by choosing a very similar and very dissimilar image to the anchor image. This allows us to define a ranking loss in which we encourage the L2 norm of the features from similar images to be small, and the L2 norm of the features from dissimilar images to be large. Although this already gives good performance, by further combining this with a small classification network and a classification loss on the dissimilar image, results can be further improved. In contrast with using features directly from classification networks, our features are optimized as an embedding using L2 norm and thus the Euclidean distance can be used directly to provide t-SNE visualizations and also similarity queries using KD-trees.
Results
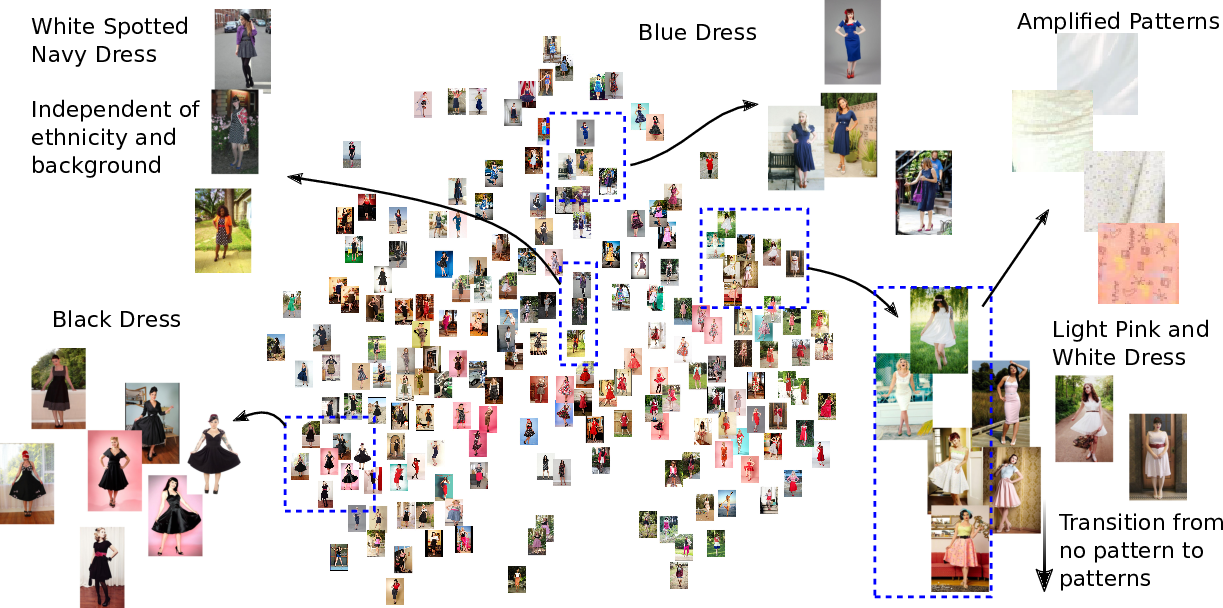
We train our model on the Fashion144k dataset and evaluate our features both qualitatively and quantitatively on the Hipsters Wars dataset1. Above we show a visualization using t-SNE2 on the Pinup class of the Hipster Wars dataset. We can see our approach is able to group different outfits ignoring the background and the wearer. For the full visualization, click here.
For full results and details please consult the full paper.
This research was partially funded by JST CREST.


{kind=link}