Datasets
This is a list of datasets I provide for reproduction of paper results
and to further encourage same lines of research. Note that these datasets are meant for
education and research purposes only. Please read the readme of each dataset that is
included in the download for more detailed information.
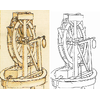
We present a line drawing restoration dataset which consists of 71 line drawing
sketches by Leonardo Da Vinci.

This extends the previous Fashion144k dataset to have a much larger number of
images, and uses the automatic curating approach proposed in our StyleNet paper to
improve the quality of the images. To evaluate learning with noisy labels, we
provide a selected subset of 66 noisy tags for all the images, and additionally
provide a subset of manually curated tags for both training and evaluation.

We present the FashionStyle14 dataset which focuses on predicting the fashion style
of images. The images focus on single individuals with fully visible poses. We
provide expert-curated fashion style annotations for a total of 14 unique
challenging classes that focus on modern Japanese fashion styles such as Gal,
Natural, or Casual.

We present an automatically curated version of the Fashion144k dataset. In order to
improve the quality of images, we annotated a small subset of images in which a
single individual is roughly centered in the image as positive images. We then
train a convolutional network in order to predict whether an image is positive or
not, and use this network to automatically curate the rest of the dataset. Although
this reduces the number of available images, the resulting images are of much
higher quality and do not include product nor heavily distorted images.

We present the Fashion144k dataset, consisting of 144,169 user posts with images
and their associated metadata, for predicting fashionability, that is, how
fashionable the user and their outfit is in an image. We exploit the votes given to
each post by different users to obtain measure of fashionability, and provide
diverse metadata to perform analysis and predictions.

We present a dataset for the evaluation of deformation and illumination invariance
of local image patch feature point descriptors. The dataset consists of 192 unique
640x480 grayscale images corresponding to 12 different objects. Points of interest
are obtained by the Difference of Gaussians (DoG) detected and were manually
matched in order to obtain a ground truth mapping.