Publications
2026
ProjFlow: Projection Sampling with Flow Matching for Zero‑Shot Exact
Spatial Motion Control
Akihisa Watanabe, Qing Yu, Edgar Simo-Serra, Kent Fujiwara
Conference in Computer Vision and Pattern Recognition
(CVPR), 2026
Generating human motion with precise spatial control is a challenging problem.
Existing approaches often require task-specific training or slow optimization,
and enforcing hard constraints frequently disrupts motion naturalness. Building
on the observation that many animation tasks can be formulated as a linear
inverse problem, we introduce ProjFlow, a training-free sampler that achieves
zero-shot, exact satisfaction of linear spatial constraints while preserving
motion realism. Our key advance is a novel kinematics-aware metric that encodes
skeletal topology. This metric allows the sampler to enforce hard constraints by
distributing corrections coherently across the entire skeleton, avoiding the
unnatural artifacts of naive projection. Furthermore, for sparse inputs, such as
filling in long gaps between a few keyframes, we introduce a time-varying
formulation using pseudo-observations that fade during sampling. Extensive
experiments on representative applications, motion inpainting, and 2D-to-3D
lifting, demonstrate that ProjFlow achieves exact constraint satisfaction and
matches or improves realism over zero-shot baselines, while remaining competitive
with training-based controllers.
@InProceedings{WatanabeCVPR2026,
author = {Akihisa Watanabe and Qing Yu and Edgar Simo-Serra and Kent Fujiwara},
title = {{ProjFlow: Projection Sampling with Flow Matching for Zero‑Shot Exact Spatial Motion Control}}
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2026,
}
Generating high-quality motion sequences from textual descriptions has become a
prominent research area in motion synthesis. For end applications, generated
motions need to be diverse, natural, and conform to the textual description.
Furthermore, motions include factors such as style and trajectory, which are hard
to control. Finding effective ways to manage these factors is crucial for
achieving realistic motion generation. To address these challenges, we first
propose a multi-condition motion latent diffusion model that integrates style and
trajectory information into text-driven generation, enabling diverse stylized
motions and precise control with arbitrary trajectories. To preserve text
controllability, we apply an adapter that refines a pretrained text-to-motion
model by transforming the style and trajectory conditions while fully utilizing
the pretrained knowledge. Finally, during inference, we apply explicit trajectory
guidance within our classifier-free multi-guidance, ensuring that the produced
trajectories follow the intended input path. Our experimental results shows the
effectiveness of the proposed approach, achieving state-of-the-art performance in
text-to-motion generation and exhibiting high flexibility in stylized motion
synthesis. Our work unifies text-driven motion synthesis, style transfer, and
trajectory control within a single framework, paving the way for more versatile
applications in animation, human interaction, and virtual reality.
@InProceedings{FangluICASSP2026,
author = {Fanglu Xie, Tsukasa Shiota, Motohiro Takagi, Edgar Simo-Serra},
title = {{Stylized Text-to-Motion Synthesis via Multi-condition Latent Diffusion}},
booktitle = "Proceedings of the IEEE International Conference on Acoustics, Speeche, and Signal Processing (ICASSP)",
year = 2026,
}
Large-scale terrain generation remains a challenging labor-intensive procedural
content generation task in computer graphics. To allow controllable creation at a
large scale, in this work, we introduce Geodiffussr, a flow matching-based
pipeline that generates realistic, text prompt-guided texture map while strictly
respecting an input Digital Elevation Map (DEM). We fuse geometry into the UNet
at coarse-to-fine resolutions with Multi-scale Content-Aggregation (MCA),
allowing the model to respect global landforms and local ridgelines alike.
Compared with a non-MCA baseline, MCA markedly improves visual fidelity and
strengthens the correlation between height and color. We train the model with a
new dataset of global terrain that contains DEM, satellite images, and
corresponding prompt annotations.
@Article{InuiCVMTB2026,
author = {Tai Inui and Alexander Matsumura and Edgar Simo-Serra},
title = {{Geodiffussr: Generative Terrain Texturing with Elevation Fidelity}},
journal = {{Computational Visual Media Technical Brief}},
year = 2026,
}
Neural rendering provides a fundamentally new way to render photorealistic
images. Similar to traditional light-baking methods, neural rendering utilizes
neural networks to bake representations of scenes, materials, and lights into
latent vectors learned from path-tracing ground truths. However, existing neural
rendering algorithms typically use G-buffers to provide position, normal, and
texture information of scenes, which are prone to occlusion by transparent
surfaces, leading to distortions and loss of detail in the rendered images. To
address this limitation, we propose a novel neural rendering pipeline that
accurately renders the scene behind transparent surfaces with global illumination
and variable scenes. Our method separates the G-buffers of opaque and transparent
objects, retaining G-buffer information behind transparent objects. Additionally,
to render the transparent objects with permutation invariance, we designed a new
permutation-invariant neural blending function. We integrate our algorithm into
an efficient custom renderer to achieve real-time performance. Our results show
that our method is capable of rendering photorealistic images with variable
scenes and viewpoints, accurately capturing complex transparent structures along
with global illumination. Our renderer can achieve real-time performance (256x256
at 63 FPS and 512x512 at 32 FPS) on scenes with multiple variable transparent
objects.
@Article{ZiyangCVM2024,
author = {Ziyang Zhang and Edgar Simo-Serra},
title = {{Deep Sketch Vectorization via Implicit Surface Extraction}},
journal = "Computational Visual Media",
year = 2025,
volume = 12,
number = 2,
}
2025
Creating high-quality line art in a fast and controlled manner plays a crucial
role in anime production and concept design. We present DoodleAssist, an
interactive and progressive line art generation system controlled by sketches and
prompts, which helps both experts and novices concretize their design intentions
or explore possibilities. Built upon a controllable diffusion model, our system
performs progressive generation based on the last generated line art,
synthesizing regions corresponding to drawn or modified strokes while keeping the
remaining ones unchanged. To facilitate this process, we propose a latent
distribution alignment mechanism to enhance the transition between the two
regions and allow seamless blending, thereby alleviating issues of region
incoherence and line discontinuity. Finally, we also build a user interface that
allows the convenient creation of line art through interactive sketching and
prompts. Qualitative and quantitative comparisons against existing approaches and
an in-depth user study demonstrate the effectiveness and usability of our system.
Our system can benefit various applications such as anime concept design, drawing
assistant, and creativity support for children.
@Article{HaoranTVCG2025,
author = {Haoran Mo and Yulin Shen and Edgar Simo-Serra and Zeyu Wang},
title = {{DoodleAssist: Progressive Interactive Line Art Generation with Latent Distribution Alignment"}},
journal = "IEEE Transactions on Visualization and Computer Graphics",
year = 2025,
volume = 32,
number = 2,
}

Multimodal Markup Document Models for Graphic Design
Completion
Kotaro Kikuchi, Ukyo Honda, Naoto Inoue, Mayu Otani, Edgar Simo-Serra, Kota
Yamaguchi
ACM International Conference on Multimedia, 2025
This paper presents multimodal markup document models (MarkupDM) that can
generate both markup language and images within interleaved multimodal documents.
Unlike existing vision-and-language multimodal models, our MarkupDM tackles
unique challenges critical to graphic design tasks: generating partial images
that contribute to the overall appearance, often involving transparency and
varying sizes, and understanding the syntax and semantics of markup languages,
which play a fundamental role as a representational format of graphic designs. To
address these challenges, we design an image quantizer to tokenize images of
diverse sizes with transparency and modify a code language model to process
markup languages and incorporate image modalities. We provide in-depth
evaluations of our approach on three graphic design completion tasks: generating
missing attribute values, images, and texts in graphic design templates. Results
corroborate the effectiveness of our MarkupDM for graphic design tasks. We also
discuss the strengths and weaknesses in detail, providing insights for future
research on multimodal document generation.
@InProceedings{KikuchiMM2025,
author = {Kotaro Kikuchi and Edgar Simo-Serra and Mayu Otani and Kota Yamaguchi},
author = {Kotaro Kikuchi and Ukyo Honda and Naoto Inoue and Mayu Otani and Edgar Simo-Serra and Kota Yamaguchi},
title = {{Multimodal Markup Document Models for Graphic Design Completion}},
booktitle = "Proceedings of the ACM International Conference on Multimedia (MM)",
year = 2025,
}
We propose a novel neural global illumination baking method for real-time
stereoscopic rendering, with applications to virtual reality. Naively, applying
neural global illumination to stereoscopic rendering requires running the model
per eye, which doubles the computational cost making it infeasible for real-time
virtual reality applications. Training a stereoscopic model from scratch is also
impractical, as it will require additional path tracing ground truth for both
eyes. We overcome these limitations by first training a common neural global
illumination baking model using a single eye dataset. We then use self-supervised
learning to train a second stereoscopic model using the first model as a teacher
model, where we also transfer the weights of the first model to the second model
to accelerate the training process. Furthermore, our spatial coherence loss
encourages consistency between the rendering for two eyes. Experiments show our
method achieves the same quality as the original single-eye model with minimal
overhead, enabling real-time performance in virtual reality.
@Article{ZiyangPGP2025,
author = {Ziyang Zhang and Edgar Simo-Serra},
title = {{Self-Supervised Neural Global Illumination for Stereo-Rendering}},
journal = {Pacific Graphics Posters}},
year = 2025,
}
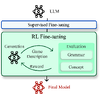
Game Description Generation (GDG) is the task of generating a game description
written in a Game Description Language (GDL) from natural language text. Previous
studies have explored generation methods leveraging the contextual understanding
capabilities of Large Language Models (LLMs); however, accurately reproducing the
game features of the game descriptions remains a challenge. In this paper, we
propose reinforcement learning-based fine-tuning of LLMs for GDG (RLGDG). Our
training method simultaneously improves grammatical correctness and fidelity to
game concepts by introducing both grammar rewards and concept rewards.
Furthermore, we adopt a two-stage training strategy where Reinforcement Learning
(RL) is applied following Supervised Fine-Tuning (SFT). Experimental results
demonstrate that our proposed method significantly outperforms baseline methods
using SFT alone.
@InProceedings{TanakaCOG2025,
author = {Tsunehiko Tanaka and Edgar Simo-Serra},
title = {{Grammar and Gameplay-aligned RL for Game Description Generation with LLMs}},
booktitle = "Proceedings of the Conference on Games (CoG)",
year = 2025,
}
We propose a neural screen-space refraction baking method for global illumination
rendering, with applicability to real-time 3D games. Existing neural global
illumination rendering methods often struggle with refractive objects due to the
lack of texture information in G-Buffers. While some existing approaches extend
neural global illumination to refractive objects by predicting texture maps (UV
maps), they are limited to objects with simple geometry and UV maps. In contrast,
our method bakes refracted textures without these assumptions by directly
encoding the world coordinates of refracted objects into the neural network
instead of UV coordinates. Our experiments demonstrate that our approach performs
better on refraction rendering than previous methods. Additionally, we
investigate the differences in neural network performance when baking coordinates
in different spaces, such as world space, screen space, and UV space, showing the
best results yielded by baking in world-space coordinates.
@InProceedings{ZiyangCVPRW2023,
author = {Ziyang Zhang and Edgar Simo-Serra},
title = {{G-Buffer Supported Neural Screen-space Refraction Baking for Real-Time Global Illumination}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2025,
}
Traditional approaches in offline reinforcement learning aim to learn the optimal
policy that maximizes the cumulative reward, also known as return. It is
increasingly important to adjust the performance of AI agents to meet human
requirements, for example, in applications like video games and education tools.
Decision Transformer (DT) optimizes a policy that generates actions conditioned
on the target return through supervised learning and includes a mechanism to
control the agent's performance using the target return. However, the action
generation is hardly influenced by the target return because DT’s self-attention
allocates scarce attention scores to the return tokens. In this paper, we propose
Return-Aligned Decision Transformer (RADT), designed to more effectively align
the actual return with the target return. RADT leverages features extracted by
paying attention solely to the return, enabling action generation to consistently
depend on the target return. Extensive experiments show that RADT significantly
reduces the discrepancies between the actual return and the target return
compared to DT-based methods.
@Article{TanakaTMLR2024,
author = {Tsunehiko Tanaka and Kenshi Abe and Kaito Ariu and Tetsuro Morimura and Edgar Simo-Serra},
title = {{Return-Aligned Decision Transformer}},
journal = "Transactions on Machine Learning Research (Presented at ICML 2026)",
year = 2025,
volume = 1,
number = 1,
}
Image generation in the fashion domain has predominantly focused on preserving
body characteristics or following input prompts, but little attention has been
paid to improving the inherent fashionability of the output images. This paper
presents a novel diffusion model-based approach that generates fashion images
with improved fashionability while maintaining control over key attributes. Key
components of our method include: 1) fashionability enhancement, which ensures
that the generated images are more fashionable than the input; 2) preservation of
body characteristics, encouraging the generated images to maintain the original
shape and proportions of the input; and 3) automatic fashion optimization, which
does not rely on manual input or external prompts. We also employ two methods to
collect training data for guidance while generating and evaluating the images. In
particular, we rate outfit images using fashionability scores annotated by
multiple fashion experts through OpenSkill-based and five critical aspect-based
pairwise comparisons. These methods provide complementary perspectives for
assessing and improving the fashionability of the generated images. The
experimental results show that our approach outperforms the baseline Fashion++ in
generating images with superior fashionability, demonstrating its effectiveness
in producing more stylish and appealing fashion images.
@InProceedings{QiceWACV2025,
author = {Qice Qin and Yuki Hirakawa and Ryotaro Shimizu and Takuya Furusawa and Edgar Simo-Serra},
title = {{Fashionability-Enhancing Outfit Image Editing with Conditional Diffusion Models}},
booktitle = "Proceedings of the Winter Conference on Applications of Computer Vision Workshops (WACVW)",
year = 2025,
}
2024
Game Description Language (GDL) provides a standardized way to express diverse
games in a machine-readable format, enabling automated game simulation, and
evaluation. While previous research has explored game description generation
using search-based methods, generating GDL descriptions from natural language
remains a challenging task. This paper presents a novel framework that leverages
Large Language Models (LLMs) to generate grammatically accurate game descriptions
from natural language. Our approach consists of two stages: first, we gradually
generate a minimal grammar based on GDL specifications; second, we iteratively
improve the game description through grammar-guided generation. Our framework
employs a specialized parser that identifies valid subsequences and candidate
symbols from LLM responses, enabling gradual refinement of the output to ensure
grammatical correctness. Experimental results demonstrate that our iterative
improvement approach significantly outperforms baseline methods that directly use
LLM outputs.
@Article{TanakaTOG2024,
author = {Tsunehiko Tanaka and Edgar Simo-Serra},
title = {{Grammar-based Game Description Generation using Large Language Models}},
journal = "Transactions on Games",
year = 2024,
volume = 1,
number = 1,
}
Neural rendering bakes global illumination and other computationally costly
effects into the weights of a neural network, allowing to efficiently synthesize
photorealistic images without relying on path tracing. In neural rendering
approaches, G-buffers obtained from rasterization through direct rendering
provide information regarding the scene such as position, normal, and textures to
the neural network, achieving accurate and stable rendering quality in real-time.
However, due to the use of G-buffers, existing methods struggle to accurately
render transparency and refraction effects, as G-buffers do not capture any ray
information from multiple light ray bounces. This limitation results in
blurriness, distortions, and loss of detail in rendered images that contain
transparency and refraction, and is particularly notable in scenes with refracted
objects that have high-frequency textures. In this work, we propose a neural
network architecture to encode critical rendering information, including texture
coordinates from refracted rays, and enable reconstruction of high-frequency
textures in areas with refraction. Our approach is able to achieves accurate
refraction rendering in challenging scenes with a diversity of overlapping
transparent objects. Experimental results demonstrate that our method can
interactively render high quality refraction effects with global illumination,
unlike existing neural rendering approaches.
@Article{ZiyangPG2024,
author = {Ziyang Zhang and Edgar Simo-Serra},
title = {{CrystalNet: Texture-Aware Neural Refraction Baking for Global Illumination}},
journal = {Computer Graphics Forum (Pacific Graphics)},
year = 2024,
}

Deep Sketch Vectorization via Implicit Surface Extraction
Chuan Yan, Yong Li, Deepali Aneja, Matthew Fisher, Edgar Simo-Serra, Yotam
Gingold
ACM Transactions on Graphics (SIGGRAPH), 2024
We introduce an algorithm for sketch vectorization with state-of-the-art accuracy
and capable of handling complex sketches. We approach sketch vectorization as a
surface extraction task from an unsigned distance field, which is implemented
using a two-stage neural network and a dual contouring domain post processing
algorithm. This word is normally spelled with a hyphen. The first stage consists
of extracting unsigned distance fields from an input raster image. The second
stage consists of an improved neural dual contouring network more robust to noisy
input and more sensitive to line geometry. To address the issue of under-sampling
inherent in grid-based surface extraction approaches, we explicitly predict
undersampling and keypoint maps. These are used in our post-processing algorithm
to resolve sharp features and multi-way junctions. The keypoint and undersampling
maps are naturally controllable, which we demonstrate in an interactive topology
refinement interface. Our proposed approach produces far more accurate
vectorizations on complex input than previous approaches with efficient running
time.
@Article{ChuanSIGGRAPH2024,
author = {Chuan Yan and Yong Li and Deepali Aneja and Matthew Fisher and Edgar Simo-Serra and Yotam Gingold},
title = {{Deep Sketch Vectorization via Implicit Surface Extraction}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2024,
volume = 43,
number = 4,
}
There exists a large number of old films that have not only artistic value but
also historical significance. However, due to the degradation of analogue medium
over time, old films often suffer from various deteriorations that make it
difficult to restore them with existing approaches. In this work, we proposed a
novel framework called Recursive Recurrent Transformer Network (RRTN) which is
specifically designed for restoring degraded old films. Our approach introduces
several key advancements, including a more accurate film noise mask estimation
method, the utilization of second-order grid propagation and flow-guided
deformable alignment, and the incorporation of a recursive structure to further
improve the removal of challenging film noise. Through qualitative and
quantitative evaluations, our approach demonstrates superior performance compared
to existing approaches, effectively improving the restoration for difficult film
noises that cannot be perfectly handled by existing approaches.
@InProceedings{LinWACV2024,
author = {Shan Lin and Edgar Simo-Serra},
title = {{Restoring Degraded Old Films with Recursive Recurrent Transformer Networks}},
booktitle = "Proceedings of the Winter Conference on Applications of Computer Vision (WACV)",
year = 2024,
}
2023

We present a novel framework for rectifying occlusions and distortions in
degraded texture samples from natural images. Traditional texture synthesis
approaches focus on generating textures from pristine samples, which necessitate
meticulous preparation by humans and are often unattainable in most natural
images. These challenges stem from the frequent occlusions and distortions of
texture samples in natural images due to obstructions and variations in object
surface geometry. To address these issues, we propose a framework that
synthesizes holistic textures from degraded samples in natural images, extending
the applicability of exemplar-based texture synthesis techniques. Our framework
utilizes a conditional Latent Diffusion Model (LDM) with a novel occlusion-aware
latent transformer. This latent transformer not only effectively encodes texture
features from partially-observed samples necessary for the generation process of
the LDM, but also explicitly captures long-range dependencies in samples with
large occlusions. To train our model, we introduce a method for generating
synthetic data by applying geometric transformations and free-form mask
generation to clean textures. Experimental results demonstrate that our framework
significantly outperforms existing methods both quantitatively and
quantitatively. Furthermore, we conduct comprehensive ablation studies to
validate the different components of our proposed framework. Results are
corroborated by a perceptual user study which highlights the efficiency of our
proposed approach.
@Inproceedings{HaoSIGGRAPHASIA2023,
author = {Guoqing Hao and Satoshi Iizuka and Kensho Hara and Edgar Simo-Serra and Hirokatsu Kataoka and Kazuhiro Fukui},
title = {{Diffusion-based Holistic Texture Rectification and Synthesis}},
booktitle = "ACM SIGGRAPH Asia 2023 Conference Papers",
year = 2023,
}

Although digital painting has advanced much in recent years, there is still a
significant divide between physically drawn paintings and purely digitally drawn
paintings. These differences arise due to the physical interactions between the
brush, ink, and paper, which are hard to emulate in the digital domain. Most ink
painting approaches have focused on either using heuristics or physical
simulation to attempt to bridge the gap between digital and analog, however,
these approaches are still unable to capture the diversity of painting effects,
such as ink fading or blotting, found in the real world. In this work, we propose
a data-driven approach to generate ink paintings based on a semi-automatically
collected high-quality real-world ink painting dataset. We use a multi-camera
robot-based setup to automatically create a diversity of ink paintings, which
allows for capturing the entire process in high resolution, including capturing
detailed brush motions and drawing results. To ensure high-quality capture of the
painting process, we calibrate the setup and perform occlusion-aware blending to
capture all the strokes in high resolution in a robust and efficient way. Using
our new dataset, we propose a recursive deep learning-based model to reproduce
the ink paintings stroke by stroke while capturing complex ink painting effects
such as bleeding and mixing. Our results corroborate the fidelity of the proposed
approach to real hand-drawn ink paintings in comparison with existing approaches.
We hope the availability of our dataset will encourage new research on digital
realistic ink painting techniques.
@Article{MadonoPG2023,
author = {Koki Madono and Edgar Simo-Serra},
title = {{Data-Driven Ink Painting Brushstroke Rendering}},
journal = {Computer Graphics Forum (Pacific Graphics)},
year = 2023,
}
Neural Global Illumination for Permutation Invariant
Transparency
Ziyang Zhang, Edgar Simo-Serra
Visual Computing (ショートオーラル), 2023
Recursive Recurrent Transformer Network for Degraded Film
Restoration
Shan Lin, Edgar Simo-Serra
Visual Computing (ショートオーラル), 2023
Diffusion-based Holistic Texture Rectification and Synthesis
Guoqing Hao, Satoshi Iizuka, Kensho Hara, Edgar Simo-Serra, Hirokatsu Kataoka,
Kazuhiro Fukui
Visual Computing (ロングオーラル), 2023
This study introduces a novel methodology for generating levels in the iconic
video game Super Mario Bros. using a diffusion model based on a UNet
architecture. The model is trained on existing levels, represented as a
categorical distribution, to accurately capture the game’s fundamental mechanics
and design principles. The proposed approach demonstrates notable success in
producing high-quality and diverse levels, with a significant proportion being
playable by an artificial agent. This research emphasizes the potential of
diffusion models as an efficient tool for procedural content generation and
highlights their potential impact on the development of new video games and the
enhancement of existing games through generated content.
@InProceedings{LeeMVA2023,
author = {Hyeon Joon Lee and Edgar Simo-Serra},
title = {{Using Unconditional Diffusion Models in Level Generation for Super Mario Bros.}},
booktitle = "International Conference on Machine Vision Applications (MVA)",
year = 2023,
}
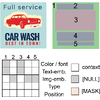
Towards Flexible Multi-modal Document Models
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi
Conference in Computer Vision and Pattern Recognition
(CVPR), 2023
Creative workflows for generating graphical documents involve complex
inter-related tasks, such as aligning elements, choosing appropriate fonts, or
employing aesthetically harmonious colors. In this work, we attempt at building a
holistic model that can jointly solve many different design tasks. Our model,
which we denote by FlexDM, treats vector graphic documents as a set of
multi-modal elements, and learns to predict masked fields such as element type,
position, styling attributes, image, or text, using a unified architecture.
Through the use of explicit multi-task learning and in-domain pre-training, our
model can better capture the multi-modal relationships among the different
document fields. Experimental results corroborate that our single FlexDM is able
to successfully solve a multitude of different design tasks, while achieving
performance that is competitive with task-specific and costly baselines.
@InProceedings{InoueCVPR2023b,
title = {{Towards Flexible Multi-modal Document Models}},
author = {Naoto Inoue and Kotaro Kikuchi and Edgar Simo-Serra and Mayu Otani and Kota Yamaguchi},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2023,
}
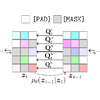
LayoutDM: Discrete Diffusion Model for Controllable Layout
Generation
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi
Conference in Computer Vision and Pattern Recognition
(CVPR), 2023
Controllable layout generation aims at synthesizing plausible arrangement of
element bounding boxes with optional constraints, such as type or position of a
specific element. In this work, we try to solve a broad range of layout
generation tasks in a single model that is based on discrete state-space
diffusion models. Our model, named LayoutDM, naturally handles the structured
layout data in the discrete representation and learns to progressively infer a
noiseless layout from the initial input, where we model the layout corruption
process by modality-wise discrete diffusion. For conditional generation, we
propose to inject layout constraints in the form of masking or logit adjustment
during inference. We show in the experiments that our LayoutDM successfully
generates high-quality layouts and outperforms both task-specific and
task-agnostic baselines on several layout tasks.
@InProceedings{InoueCVPR2023a,
title = {{LayoutDM: Discrete Diffusion Model for Controllable Layout Generation}},
author = {Naoto Inoue and Kotaro Kikuchi and Edgar Simo-Serra and Mayu Otani and Kota Yamaguchi},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2023,
}
Colorization of line art drawings is an important task in illustration and
animation workflows. However, this highly laborious process is mainly done
manually, limiting the creative productivity. This paper presents a novel
interactive approach for line art colorization using conditional Diffusion
Probabilistic Models (DPMs). In our proposed approach, the user provides initial
color strokes for colorizing the line art. The strokes are then integrated into
the conditional DPM-based colorization process by means of a coupled implicit and
explicit conditioning strategy to generates diverse and high-quality colorized
images. We evaluate our proposal and show it outperforms existing
state-of-the-art approaches using the FID, LPIPS and SSIM metrics.
@InProceedings{CarrilloCVPRW2023,
author = {Hernan Carrillo and Micha\"el Cl/'ement and Aur\'elie Bugeau and Edgar Simo-Serra},
title = {{Diffusart: Enhancing Line Art Colorization with Conditional Diffusion Models}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2023,
}

Controllable Multi-domain Semantic Artwork Synthesis
Yuantian Huang, Satoshi Iizuka, Edgar Simo-Serra, Kazuhiro Fukui
Computational Visual Media, 2023
We present a novel framework for multi-domain synthesis of artwork from semantic
layouts. One of the main limitations of this challenging task is the lack of
publicly available segmentation datasets for art synthesis. To address this
problem, we propose a dataset, which we call ArtSem, that contains 40,000 images
of artwork from 4 different domains with their corresponding semantic label maps.
We generate the dataset by first extracting semantic maps from landscape
photography and then propose a conditional Generative Adversarial Network
(GAN)-based approach to generate high-quality artwork from the semantic maps
without necessitating paired training data. Furthermore, we propose an artwork
synthesis model that uses domain-dependent variational encoders for high-quality
multi-domain synthesis. The model is improved and complemented with a simple but
effective normalization method, based on normalizing both the semantic and style
jointly, which we call Spatially STyle-Adaptive Normalization (SSTAN). In
contrast to previous methods that only take semantic layout as input, our model
is able to learn a joint representation of both style and semantic information,
which leads to better generation quality for synthesizing artistic images.
Results indicate that our model learns to separate the domains in the latent
space, and thus, by identifying the hyperplanes that separate the different
domains, we can also perform fine-grained control of the synthesized artwork. By
combining our proposed dataset and approach, we are able to generate
user-controllable artwork that is of higher quality than existing approaches, as
corroborated by both quantitative metrics and a user study.
@Article{HuangCVM2023,
title = {{Controllable Multi-domain Semantic Artwork Synthesis}},
author = {Yuantian Huang and Satoshi Iizuka and Edgar Simo-Serra and Kazuhiro Fukui},
journal = "Computational Visual Media",
year = 2023,
volume = 39,
number = 2,
}
Color is a critical design factor for web pages, affecting important factors such
as viewer emotions and the overall trust and satisfaction of a website. Effective
coloring re- quires design knowledge and expertise, but if this process could be
automated through data-driven modeling, efficient exploration and alternative
workflows would be possible. However, this direction remains underexplored due to
the lack of a formalization of the web page colorization prob- lem, datasets, and
evaluation protocols. In this work, we propose a new dataset consisting of
e-commerce mobile web pages in a tractable format, which are created by simplify-
ing the pages and extracting canonical color styles with a common web browser.
The web page colorization problem is then formalized as a task of estimating
plausible color styles for a given web page content with a given hierarchical
structure of the elements. We present several Transformer- based methods that are
adapted to this task by prepending structural message passing to capture
hierarchical relation- ships between elements. Experimental results, including a
quantitative evaluation designed for this task, demonstrate the advantages of our
methods over statistical and image colorization methods.
@InProceedings{KikuchiWACV2023,
author = {Kotaro Kikuchi and Naoto Inoue and Mayo Otani and Edgar Simo-Serra and Kota Yamaguchi},
title = {{Generative Colorization of Structured Mobile Web Pages}},
booktitle = "Proceedings of the Winter Conference on Applications of Computer Vision (WACV)",
year = 2023,
}
2022
Image Synthesis-based Late Stage Cancer Augmentation and
Semi-Supervised Segmentation for MRI Rectal Cancer Staging
Saeko Sasuga, Akira Kudo, Yoshiro Kitamura, Satoshi Iizuka, Edgar Simo-Serra,
Atsushi Hamabe, Masayuki Ishii, Ichiro Takemasa
International Conference on Medical Image Computing and Computer Assisted
Intervention Workshops (MICCAIW), 2022
Rectal cancer is one of the most common diseases and a major cause of mortality.
For deciding rectal cancer treatment plans, T- staging is important. However,
evaluating the index from preoperative MRI images requires high radiologists’
skill and experience. Therefore, the aim of this study is to segment the
mesorectum, rectum, and rectal cancer region so that the system can predict
T-stage from segmentation results. Generally, shortage of large and diverse
dataset and high quality an- notation are known to be the bottlenecks in computer
aided diagnos- tics development. Regarding rectal cancer, advanced cancer images
are very rare, and per-pixel annotation requires high radiologists’ skill and
time. Therefore, it is not feasible to collect comprehensive disease pat- terns
in a training dataset. To tackle this, we propose two kinds of ap- proaches of
image synthesis-based late stage cancer augmentation and semi-supervised learning
which is designed for T-stage prediction. In the image synthesis data
augmentation approach, we generated advanced cancer images from labels. The real
cancer labels were deformed to re- semble advanced cancer labels by artificial
cancer progress simulation. Next, we introduce a T-staging loss which enables us
to train segmen- tation models from per-image T-stage labels. The loss works to
keep inclusion/invasion relationships between rectum and cancer region con-
sistent to the ground truth T-stage. The verification tests show that the
proposed method obtains the best sensitivity (0.76) and specificity (0.80) in
distinguishing between over T3 stage and underT2. In the ab- lation studies, our
semi-supervised learning approach with the T-staging loss improved specificity by
0.13. Adding the image synthesis-based data augmentation improved the DICE score
of invasion cancer area by 0.08 from baseline. We expect that this rectal cancer
staging AI can help doctors to diagnose cancer staging accurately.
@InProceedings{SasugaMICCAIW2022,
author = {Saeko Sasuga and Akira Kudo and Yoshiro Kitamura and Satoshi Iizuka and Edgar Simo-Serra and Atsushi Hamabe and Masayuki Ishii and Ichiro Takemasa},
title = {{Image Synthesis-based Late Stage Cancer Augmentation and Semi-Supervised Segmentation for MRI Rectal Cancer Staging}},
booktitle = "Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention Workshops (MICCAIW)",
year = 2022,
}
Dealing with unstructured complex patterns provides a challenge to existing
reinforcement patterns. In this research, we propose a new model to overcome the
difficulty in challenging danmaku games. Touhou Project is one of the best-known
games in the bullet hell genre also known as danmaku, where a player has to dodge
complex patterns of bullets on the screen. Furthermore, the agent needs to react
to the environment in real-time, which made existing methods having difficulties
processing the high-volume data of objects; bullets, enemies, etc. We introduce
an environment for the Touhou Project game 東方花映塚 ~ Phantasmagoria of Flower View
which manipulates the memory of the running game and enables to control the
character. However, the game state information consists of unstructured and
unordered data not amenable for training existing reinforcement learning models,
as they are not invariant to order changes in the input. To overcome this issue,
we propose a new pooling-based reinforcement learning approach that is able to
handle permutation invariant inputs by extracting abstract values and merging
them in an order-independent way. Experimental results corroborate the
effectiveness of our approach which shows significantly increased scores compared
to existing baseline approaches.
@InProceedings{ItoiCOG2022,
author = {Takuto Itoi and Edgar Simo-Serra},
title = {{PIFE: Permutation Invariant Feature Extractor for Danmaku Games}},
booktitle = "Proceedings of the Conference on Games (CoG, Short Oral)",
year = 2022,
}
Towards Universal Multi-Modal Layout Models
Naoto Inoue, Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi
第22回画像の認識・理解シンポジウム(MIRU、ロングオーラル), 2022
2021
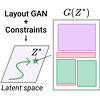
It is common in graphic design humans visually arrange various elements according
to their design intent and semantics. For example, a title text almost always
appears on top of other elements in a document. In this work, we generate graphic
layouts that can flexibly incorporate such design semantics, either specified
implicitly or explicitly by a user. We optimize using the latent space of an
off-the-shelf layout generation model, allowing our approach to be complementary
to and used with existing layout generation models. Our approach builds on a
generative layout model based on a Transformer architecture, and formulates the
layout generation as a constrained optimization problem where design constraints
are used for element alignment, overlap avoidance, or any other user-specified
relationship. We show in the experiments that our approach is capable of
generating realistic layouts in both constrained and unconstrained generation
tasks with a single model.
@InProceedings{KikuchiMM2021,
author = {Kotaro Kikuchi and Edgar Simo-Serra and Mayu Otani and Kota Yamaguchi},
title = {{Constrained Graphic Layout Generation via Latent Optimization}},
booktitle = "Proceedings of the ACM International Conference on Multimedia (MM)",
year = 2021,
}
Web pages have become fundamental in conveying information for companies and
individuals, yet designing web page layouts remains a challenging task for
inexperienced individuals despite web builders and templates. Visual containment,
in which elements are grouped together and placed inside container elements, is
an efficient design strategy for organizing elements in a limited display, and is
widely implemented in most web page designs. Yet, visual containment has not been
explicitly addressed in the research on generating layouts from scratch, which
may be due to the lack of hierarchical structure. In this work, we represent such
visual containment as a layout tree, and formulate the layout design task as a
hierarchical optimization problem. We first estimate the layout tree from a given
a set of elements, which is then used to compute tree-aware energies
corresponding to various desirable design properties such as alignment or
spacing. Using an optimization approach also allows our method to naturally
incorporate user intentions and create an interactive web design application. We
obtain a dataset of diverse and popular real-world web designs to optimize and
evaluate various aspects of our method. Experimental results show that our method
generates better quality layouts compared to the baseline method.
@Article{KikuchiPG2021,
author = {Kotaro Kikuchi and Edgar Simo-Serra and Mayu Otani and Kota Yamaguchi},
title = {{Modeling Visual Containment for Web Page Layout Optimization}},
journal = {Computer Graphics Forum (Pacific Graphics)},
year = 2021,
}
Exploring Latent Space for Constrained Layout Generation
Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi
Visual Computing (ロングオーラル), 2021
Hierarchical Layout Optimization with Containment-aware
Parameterization
Kotaro Kikuchi, Edgar Simo-Serra, Mayu Otani, Kota Yamaguchi
Visual Computing (ロングオーラル), 2021
Item Management Using Attention Mechanism and Meta Actions in Roguelike
Games
Keisuki Izumiya, Edgar Simo-Serra
Visual Computing (ロングオーラル), 2021
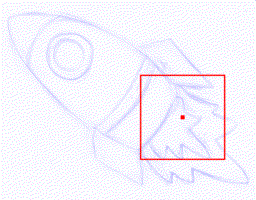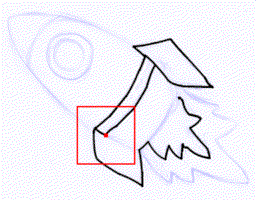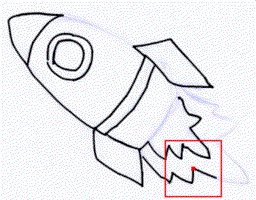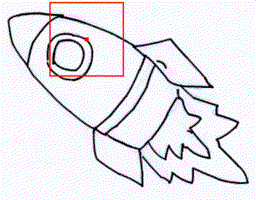
Vector line art plays an important role in graphic design, however, it is tedious
to manually create. We introduce a general framework to produce line drawings
from a wide variety of images, by learning a mapping from raster image space to
vector image space. Our approach is based on a recurrent neural network that
draws the lines one by one. A differentiable rasterization module allows for
training with only supervised raster data. We use a dynamic window around a
virtual pen while drawing lines, implemented with a proposed aligned cropping and
differentiable pasting modules. Furthermore, we develop a stroke regularization
loss that encourages the model to use fewer and longer strokes to simplify the
resulting vector image. Ablation studies and comparisons with existing methods
corroborate the efficiency of our approach which is able to generate visually
better results in less computation time, while generalizing better to a diversity
of images and applications.
@Article{HaoranSIGGRAPH2021,
author = {Haoran Mo and Edgar Simo-Serra and Chengying Gao and Changqing Zou and Ruomei Wang},
title = {{General Virtual Sketching Framework for Vector Line Art}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2021,
volume = 40,
number = 4,
}
High-quality Multi-domain Artwork Generation from Semantic
Layouts
Yuantian Huang, Satoshi Iizuka, Edgar Simo-Serra, Kazuhiro Fukui
画像の認識・理解シンポジウム(MIRU、ショートオーラル), 2021
With the ascent of wearable camera, dashcam, and autonomous vehicle technology,
fisheye lens cameras are becoming more widespread. Unlike regular cameras, the
videos and images taken with fisheye lens suffer from significant lens
distortion, thus having detrimental effects on image processing algorithms. When
the camera parameters are known, it is straight-forward to correct the
distortion, however, without known camera parameters, distortion correction
becomes a non-trivial task. While learning-based approaches exist, they rely on
complex datasets and have limited generalization. In this work, we propose a
CNN-based approach that can be trained with readily available data. We exploit
the fact that relationships between pixel coordinates remain stable after
homogeneous distortions to design an efficient rectification model. Experiments
performed on the cityscapes dataset show the effectiveness of our approach.
@InProceedings{HosonoMVA2021,
author = {Masaki Hosono and Edgar Simo-Serra and Tomonari Sonoda},
title = {{Unsupervised Deep Fisheye Image Rectification Approach using Coordinate Relations}},
booktitle = "International Conference on Machine Vision Applications (MVA)",
year = 2021,
}
Roguelike games are a challenging environment for Reinforcement Learning (RL)
algorithms due to having to restart the game from the beginning when losing,
randomized procedural generation, and proper use of in-game items being essential
to success. While recent research has proposed roguelike environments for RL
algorithms and proposed models to handle this challenging task, to the best of
our knowledge, none have dealt with the elephant in the room, i.e., handling of
items. Items play a fundamental role in roguelikes and are acquired during
gameplay. However, being an unordered set with a non-fixed amount of elements
which form part of the action space, it is not straightforward to incorporate
them into an RL framework. In this work, we tackle the issue of having unordered
sets be part of the action space and propose an attention-based mechanism that
can select and deal with item-based actions. We also propose a model that can
handle complex actions and items through a meta action framework and evaluate
them on the challenging game of NetHack. Experimental results show that our
approach is able to significantly outperform existing approaches.
@InProceedings{IzumiyaCOG2021,
author = {Keisuke Izumiya and Edgar Simo-Serra},
title = {{Inventory Managament with Attention-Based Meta Actions}},
booktitle = "Proceedings of the Conference on Games (CoG)",
year = 2021,
}

Flat filling is a critical step in digital artistic content creation with the
objective of filling line arts with flat colours. We present a deep learning
framework for user-guided line art flat filling that can compute the "influence
areas" of the user colour scribbles, i.e., the areas where the user scribbles
should propagate and influence. This framework explicitly controls such scribble
influence areas for artists to manipulate the colours of image details and avoid
colour leakage/contamination between scribbles, and simultaneously, leverages
data-driven colour generation to facilitate content creation. This framework is
based on a Split Filling Mechanism (SFM), which first splits the user scribbles
into individual groups and then independently processes the colours and influence
areas of each group with a Convolutional Neural Network (CNN). Learned from more
than a million illustrations, the framework can estimate the scribble influence
areas in a content-aware manner, and can smartly generate visually pleasing
colours to assist the daily works of artists. We show that our proposed framework
is easy to use, allowing even amateurs to obtain professional-quality results on
a wide variety of line arts.
@InProceedings{ZhangCVPR2021,
author = {Lvmin Zhang and Chengze Li and Edgar Simo-Serra and Yi Ji and Tien-Tsin Wong and Chunping Liu},
title = {{User-Guided Line Art Flat Filling with Split Filling Mechanism}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2021,
}
Line art plays a fundamental role in illustration and design, and allows for
iteratively polishing designs. However, as they lack color, they can have issues
in conveying final designs. In this work, we propose an interactive colorization
approach based on a conditional generative adversarial network that takes both
the line art and color hints as inputs to produce a high-quality colorized image.
Our approach is based on a U-net architecture with a multi-discriminator
framework. We propose a Concatenation and Spatial Attention module that is able
to generate more consistent and higher quality of line art colorization from user
given hints. We evaluate on a large-scale illustration dataset and comparison
with existing approaches corroborate the effectiveness of our approach.
@InProceedings{YuanCVPRW2021,
author = {Mingcheng Yuan and Edgar Simo-Serra},
title = {{Line Art Colorization with Concatenated Spatial Attention}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2021,
}
Esports is a fastest-growing new field with a largely online-presence, and is
creating a demand for automatic domain-specific captioning tools. However, at the
current time, there are few approaches that tackle the esports video description
problem. In this work, we propose a large-scale dataset for esports video
description, focusing on the popular game "League of Legends". The dataset, which
we call LoL-V2T, is the largest video description dataset in the vldeo game
domain, and includes 9,723 clips with 62,677 captions. This new dataset presents
multiple new video captioning challenges such as large amounts of domain-specific
vocabulary, subtle motions with large importance, and a temporal gap between most
captions and the events that occurred. In order to tackle the issue of
vocabulary, we propose a masking the domain-specific words and provide additional
annotations for this. In our results, we show that the dataset poses a challenge
to existing video captioning approaches, and the masking can significantly
improve performance.
@InProceedings{TanakaCVPRW2021,
author = {Tsunehiko Tanaka and Edgar Simo-Serra},
title = {{LoL-V2T: Large-Scale Esports Video Description Dataset}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2021,
}
Conditional human image generation, or generation of human images with specified
pose based on one or more reference images, is an inherently ill-defined problem,
as there can be multiple plausible appearance for parts that are occluded in the
reference. Using multiple images can mitigate this problem while boosting the
performance. In this work, we introduce a differentiable vertex and edge renderer
for incorporating the pose information to realize human image generation
conditioned on multiple reference images. The differentiable renderer has
parameters that can be jointly optimized with other parts of the system to obtain
better results by learning more meaningful shape representation of human pose. We
evaluate our method on the Market-1501 and DeepFashion datasets and comparison
with existing approaches validates the effectiveness of our approach.
@InProceedings{HoriuchiCVPRW2021,
author = {Yusuke Horiuchi and Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Differentiable Rendering-based Pose-Conditioned Human Image Generation}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2021,
}
2020
P²Net: A Post-Processing Network for Refining Semantic Segmentation of
LiDAR Point Cloud based on Consistency of Consecutive Frames
Yutaka Momma, Weimin Wang, Edgar Simo-Serra, Satoshi Iizuka, Ryosuke Nakamura,
Hiroshi Ishikawa
IEEE International Conference on Systems, Man, and Cybernetics, 2020
We present a lightweight post-processing method to refine the semantic
segmentation results of point cloud sequences. Most existing methods usually
segment frame by frame and encounter the inherent ambiguity of the problem: based
on a measurement in a single frame, labels are sometimes difficult to predict
even for humans. To remedy this problem, we propose to explicitly train a network
to refine these results predicted by an existing segmentation method. The
network, which we call the P²Net, learns the consistency constraints between
"coincident" points from consecutive frames after registration. We evaluate the
proposed post-processing method both qualitatively and quantitatively on the
SemanticKITTI dataset that consists of real outdoor scenes. The effectiveness of
the proposed method is validated by comparing the results predicted by two
representative networks with and without the refinement by the post-processing
network. Specifically, qualitative visualization validates the key idea that
labels of the points that are difficult to predict can be corrected with P²NNet.
Quantitatively, overall mIoU is improved from 10.5% to 11.7% for PointNet and
from 10.8% to 15.9% for PointNet++.
@InProceedings{MommaSMC2020,
author = {Yutaka Momma and Weimin Wang and Edgar Simo-Serra and Satoshi Iizuka and Ryosuke Nakamura and Hiroshi Ishikawa},
title = {{P²Net: A Post-Processing Network for Refining Semantic Segmentation of LiDAR Point Cloud based on Consistency of Consecutive Frames}},
booktitle = "Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC)",
year = 2020,
}
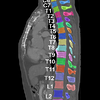
Automatic Segmentation, Localization and Identification of Vertebrae in
3D CT Images Using Cascaded Convolutional Neural Networks
Naoto Masuzawa, Yoshiro Kitamura, Keigo Nakamura, Satoshi Iizuka, Edgar
Simo-Serra
International Conference on Medical Image Computing and Computer
Assisted Intervention (MICCAI), 2020
This paper presents a method for automatic segmentation, localization, and
identification of vertebrae in arbitrary 3D CT images. Many previous works do not
perform the three tasks simultaneously even though requiring a priori knowledge
of which part of the anatomy is visible in the 3D CT images. Our method tackles
all these tasks in a single multi-stage framework without any assumptions. In the
first stage, we train a 3D Fully Convolutional Networks to find the bounding box
of the cervical, thoracic, and lumbar vertebrae. In the second stage, we train an
iterative 3D Fully Convolutional Networks to segment individual vertebrae in the
bounding box. The input to the second network has an auxiliary channel in
addition to the 3D CT images. Given the segmented vertebrae regions in the
auxiliary channel, the network output the next vertebra. The proposed method is
evaluated in terms of segmentation, localization and identification accuracy with
two public datasets of 15 3D CT images from the MICCAI CSI 2014 workshop
challenge and 302 3D CT images with various pathologies. Our method achieved a
mean Dice score of 96%, a mean localization error of 8.3 mm, and a mean
identification rate of 84%. In summary, our method achieved better performance
than all existing works in all the three metrics.
@InProceedings{MasuzawaMICCAI2020,
author = {Naoto Masuzawa and Yoshiro Kitamura and Keigo Nakamura and Satoshi Iizuka and Edgar Simo-Serra},
title = {{Automatic Segmentation, Localization and Identification of Vertebrae in 3D CT Images Using Cascaded Convolutional Neural Networks}},
booktitle = "Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI)",
year = 2020,
}
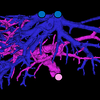
TopNet: Topology Preserving Metric Learning for Vessel Tree
Reconstruction and Labelling
Deepak Keshwani, Yoshiro Kitamura, Satoshi Ihara, Satoshi Iizuka, Edgar
Simo-Serra
International Conference on Medical Image Computing and Computer
Assisted Intervention (MICCAI), 2020
Reconstructing Portal Vein and Hepatic Vein trees from contrast enhanced
abdominal CT scans is a prerequisite for preoperative liver surgery simulation.
Existing deep learning based methods treat vascular tree reconstruction as a
semantic segmentation problem. However, vessels such as hepatic and portal vein
look very similar locally and need to be traced to their source for robust label
assignment. Therefore, semantic segmentation by looking at local 3D patch results
in noisy misclassifications. To tackle this, we propose a novel multi-task deep
learning architecture for vessel tree reconstruction. The network architecture
simultaneously solves the task of detecting voxels on vascular centerlines (i.e.
nodes) and estimates connectivity between center-voxels (edges) in the tree
structure to be reconstructed. Further, we propose a novel connectivity metric
which considers both inter-class distance and intra-class topological distance
between center-voxel pairs. Vascular trees are reconstructed starting from the
vessel source using the learned connectivity metric using the shortest path tree
algorithm. A thorough evaluation on public IRCAD dataset shows that the proposed
method considerably outperforms existing semantic segmentation based methods. To
the best of our knowledge, this is the first deep learning based approach which
learns multi-label tree structure connectivity from images.
@InProceedings{KeshwaniMICCAI2020,
author = {Deepak Keshwani and Yoshiro Kitamura and Satoshi Ihara and Satoshi Iizuka and Edgar Simo-Serra},
title = {{TopNet: Topology Preserving Metric Learning for Vessel Tree Reconstruction and Labelling}},
booktitle = "Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI)",
year = 2020,
}
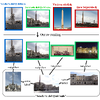
We propose an efficient pipeline for large-scale landmark image retrieval that
addresses the diversity of the dataset through two-stage discriminative
re-ranking. Our approach is based on embedding the images in a feature-space
using a convolutional neural network trained with a cosine softmax loss. Due to
the variance of the images, which include extreme viewpoint changes such as
having to retrieve images of the exterior of a landmark from images of the
interior, this is very challenging for approaches based exclusively on visual
similarity. Our proposed re-ranking approach improves the results in two steps:
in the sort-step, k-nearest neighbor search with soft-voting to sort the
retrieved results based on their label similarity to the query images, and in the
insert-step, we add additional samples from the dataset that were not retrieved
by image-similarity. This approach allows overcoming the low visual diversity in
retrieved images. In-depth experimental results show that the proposed approach
significantly outperforms existing approaches on the challenging Google Landmarks
Datasets. Using our methods, we achieved 1st place in the Google Landmark
Retrieval 2019 challenge on Kaggle.
@InProceedings{YokooCVPRW2020,
author = {Shuhei Yokoo and Kohei Ozaki and Edgar Simo-Serra and Satoshi Iizuka},
title = {{Two-stage Discriminative Re-ranking for Large-scale Landmark Retrieval}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2020,
}

We present an algorithm to generate digital painting lighting effects from a
single image. Our algorithm is based on a key observation: artists use many
overlapping strokes to paint lighting effects, i.e., pixels with dense stroke
history tend to gather more illumination strokes. Based on this observation, we
design an algorithm to both estimate the density of strokes in a digital painting
using color geometry, and then generate novel lighting effects by mimicking
artists' coarse-to-fine workflow. Coarse lighting effects are first generated
using a wave transform, and then retouched according to the stroke density of the
original illustrations into usable lighting effects.
Our algorithm is content-aware, with generated lighting effects naturally adapting to image structures, and can be used as an interactive tool to simplify current labor-intensive workflows for generating lighting effects for digital and matte paintings. In addition, our algorithm can also produce usable lighting effects for photographs or 3D rendered images. We evaluate our approach with both an in-depth qualitative and a quantitative analysis which includes a perceptual user study. Results show that our proposed approach is not only able to produce favorable lighting effects with respect to existing approaches, but also that it is able to significantly reduce the needed interaction time.
Our algorithm is content-aware, with generated lighting effects naturally adapting to image structures, and can be used as an interactive tool to simplify current labor-intensive workflows for generating lighting effects for digital and matte paintings. In addition, our algorithm can also produce usable lighting effects for photographs or 3D rendered images. We evaluate our approach with both an in-depth qualitative and a quantitative analysis which includes a perceptual user study. Results show that our proposed approach is not only able to produce favorable lighting effects with respect to existing approaches, but also that it is able to significantly reduce the needed interaction time.
@Article{ZhangTOG2020,
author = {Lvmin Zhang and Edgar Simo-Serra and Yi Ji and Chunping Liu},
title = {{Generating Digital Painting Lighting Effects via RGB-space Geometry}},
journal = "Transactions on Graphics (Presented at SIGGRAPH)",
year = 2020,
volume = 39,
number = 2,
}
2019

The remastering of vintage film comprises of a diversity of sub-tasks including
super-resolution, noise removal, and contrast enhancement which aim to restore
the deteriorated film medium to its original state. Additionally, due to the
technical limitations of the time, most vintage film is either recorded in black
and white, or has low quality colors, for which colorization becomes necessary.
In this work, we propose a single framework to tackle the entire remastering task
semi-interactively. Our work is based on temporal convolutional neural networks
with attention mechanisms trained on videos with data-driven deterioration
simulation. Our proposed source-reference attention allows the model to handle an
arbitrary number of reference color images to colorize long videos without the
need for segmentation while maintaining temporal consistency. Quantitative
analysis shows that our framework outperforms existing approaches, and that, in
contrast to existing approaches, the performance of our framework increases with
longer videos and more reference color images.
@Article{IizukaSIGGRAPHASIA2019,
author = {Satoshi Iizuka and Edgar Simo-Serra},
title = {{DeepRemaster: Temporal Source-Reference Attention Networks for Comprehensive Video Enhancement}},
journal = "ACM Transactions on Graphics (SIGGRAPH Asia)",
year = 2019,
volume = 38,
number = 6,
}
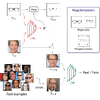
Spatially placing an object onto a background is an essential operation in
graphic design and facilitates many different applications such as virtual
try-on. The placing operation is formulated as a geometric inference problem for
given foreground and background images, and has been approached by spatial
transformer architecture.In this paper, we propose a simple yet effective
regularization technique to guide the geometric parameters based on user-defined
trust regions. Our approach stabilizes the training process of spatial
transformer networks and achieves a high-quality prediction with single-shot
inference. Our proposed method is independent of initial parameters, and can
easily incorporate various priors to prevent different types of trivial
solutions. Empirical evaluation with the Abstract Scenes and CelebA datasets
shows that our approach achieves favorable results compared to baselines.
@InProceedings{KikuchiICCVW2019,
author = {Kotaro Kikuchi and Kota Yamaguchi and Edgar Simo-Serra and Tetsunori Kobayashi},
title = {{Regularized Adversarial Training for Single-shot Virtual Try-On}},
booktitle = "Proceedings of the International Conference on Computer Vision Workshops (ICCVW)",
year = 2019,
}
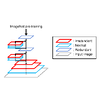
ImageNet pre-training has been regarded as essential for training accurate object
detectors for a long time. Recently, it has been shown that object detectors
trained from randomly initialized weights can be on par with those fine-tuned
from ImageNet pre-trained models. However, effect of pre-training and the
differences caused by pre-training are still not fully understood. In this paper,
we analyze the eigenspectrum dynamics of the covariance matrix of each feature
map in object detectors. Based on our analysis on ResNet-50, Faster R-CNN with
FPN, and Mask R-CNN, we show that object detectors trained from ImageNet
pre-trained models and those trained from scratch behave differently from each
other even if both object detectors have similar accuracy. Furthermore, we
propose a method for automatically determining the widths (the numbers of
channels) of object detectors based on the eigenspectrum. We train Faster R-CNN
with FPN from randomly initialized weights, and show that our method can reduce
~27% of the parameters of ResNet-50 without increasing Multiply-Accumulate
operations (MACs) and losing accuracy. Our results indicate that we should
develop more appropriate methods for transferring knowledge from image
classification to object detection (or other tasks).
@InProceedings{ShinyaICCVW2019,
author = {Yosuke Shinya and Edgar Simo-Serra and Taiji Suzuki},
title = {{Understanding the Effects of Pre-training for Object Detectors via Eigenspectrum}},
booktitle = "Proceedings of the International Conference on Computer Vision Workshops (ICCVW)",
year = 2019,
}
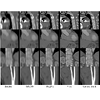
Virtual Thin Slice: 3D Conditional GAN-based Super-resolution for CT
Slice Interval
Akira Kudo, Yoshiro Kitamura, Yuanzhong Li, Satoshi Iizuka, Edgar Simo-Serra
International Conference on Medical Image Computing and Computer Assisted
Intervention Workshops (MICCAIW), 2019
Many CT slice images are stored with large slice intervals to reduce storage size
in clinical practice. This leads to low resolution perpendicular to the slice
images (i.e., z-axis), which is insufficient for 3D visualization or image
analysis. In this paper, we present a novel architecture based on conditional
Generative Adversarial Networks (cGANs) with the goal of generating high
resolution images of main body parts including head, chest, abdomen and legs.
However, GANs are known to have a difficulty with generating a diversity of
patterns due to a phenomena known as mode collapse. To overcome the lack of
generated pattern variety, we propose to condition the discriminator on the
different body parts. Furthermore, our generator networks are extended to be
three dimensional fully convolutional neural networks, allowing for the
generation of high resolution images from arbitrary fields of view. In our
verification tests, we show that the proposed method obtains the best scores by
PSNR/SSIM metrics and Visual Turing Test, allowing for accurate reproduction of
the principle anatomy in high resolution. We expect that the proposed method
contribute to effective utilization of the existing vast amounts of thick CT
images stored in hospitals.
@InProceedings{KudoMICCAIW2019,
author = {Akira Kudo and Yoshiro Kitamura and Yuanzhong Li and Satoshi Iizuka and Edgar Simo-Serra},
title = {{Virtual Thin Slice: 3D Conditional GAN-based Super-resolution for CT Slice Interval}},
booktitle = "Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention Workshops (MICCAIW)",
year = 2019,
}
Temporal Distance Matrices for Workout Form Assessment
Ryoji Ogata, Edgar Simo-Serra, Satoshi Iizuka, Hiroshi Ishikawa
第22回画像の認識・理解シンポジウム(MIRU、ショートオーラル), 2019
Regularizing Adversarial Training for Single-shot Object
Placement
Kotaro Kikuchi, Kota Yamaguchi, Edgar Simo-Serra, Tetsunori Kobayashi
第22回画像の認識・理解シンポジウム(MIRU、ショートオーラル), 2019
DeepRemaster: Temporal Source-Reference
Attentionを用いた動画のデジタルリマスター
飯塚 里志,シモセラ エドガー
Visual Computing / グラフィクスとCAD 合同シンポジウム(オーラル) [最優秀研究発表賞], 2019
The preparation of large amounts of high-quality training data has always been
the bottleneck for the performance of supervised learning methods. It is
especially time-consuming for complicated tasks such as photo enhancement. A
recent approach to ease data annotation creates realistic training data
automatically with optimization. In this paper, we improve upon this approach by
learning image-similarity which, in combination with a Covariance Matrix
Adaptation optimization method, allows us to create higher quality training data
for enhancing photos. We evaluate our approach on challenging real world
photo-enhancement images by conducting a perceptual user study, which shows that
its performance compares favorably with existing approaches.
@InProceedings{OmiyaCVPRW2019,
author = {Mayu Omiya and Yusuke Horiuchi and Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Optimization-Based Data Generation for Photo Enhancement}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2019,
}

Temporal Distance Matrices for Squat Classification
Ryoji Ogata, Edgar Simo-Serra, Satoshi Iizuka, Hiroshi Ishikawa
Conference in Computer Vision and Pattern Recognition Workshops
(CVPRW), 2019
When working out, it is necessary to perform the same action many times for it to
have effect. If the action, such as squats or bench pressing, is performed with
poor form, it can lead to serious injuries in the long term. For this purpose, we
present an action dataset of squats where different types of poor form have been
annotated with a diversity of users and backgrounds, and propose a model, based
on temporal distance matrices, for the classification task. We first run a 3D
pose detector, then we normalize the pose and compute the distance matrix, in
which each element represents the distance between two joints. This
representation is invariant to differences in individuals, global translation,
and global rotation, allowing for high generalization to real world data. Our
classification model consists of a CNN with 1D convolutions. Results show that
our method significantly outperforms existing approaches for the task.
@InProceedings{OgataCVPRW2019,
author = {Ryoji Ogata and Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Temporal Distance Matrices for Squat Classification}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2019,
}
We address the problem of conditional image generation of synthesizing a new
image of an individual given a reference image and target pose. We base our
approach on generative adversarial networks and leverage deformable skip
connections to deal with pixel-to-pixel misalignments, self-attention to leverage
complementary features in separate portions of the image, e.g., arms or legs, and
spectral normalization to improve the quality of the synthesized images. We train
the synthesis model with a nearest-neighbour loss in combination with a
relativistic average hinge adversarial loss. We evaluate on the Market-1501
dataset and show how our proposed approach can surpass existing approaches in
conditional image synthesis performance.
@InProceedings{HoriuchiMVA2019,
author = {Yusuke Horiuchi and Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Spectral Normalization and Relativistic Adversarial Training for Conditional Pose Generation with Self-Attention}},
booktitle = "International Conference on Machine Vision Applications (MVA)",
year = 2019,
}
Re-staining Pathology Images by FCNN
Masayuki Fujitani, Yoshihiko Mochizuki, Satoshi Iizuka, Edgar Simo-Serra,
Hirokazu Kobayashi, Chika Iwamoto, Kenoki Ohuchida, Makoto Hashizume, Hidekata
Hontani, Hiroshi Ishikawa
International Conference on Machine Vision Applications (MVA), 2019
In histopathology, pathologic tissue samples are stained using one of various
techniques according to the desired features to be observed in microscopic
examination. One problem is that staining is irreversible. Once a tissue slice is
stained using a technique, it cannot be re-stained using another. In this work,
we propose a method for simulated re-staining using a Fully Convolutional Neural
Network (FCNN).We convert a digitally scanned pathology image of a sample,
stained using one technique, into another image with a different simulated stain.
The challenge is that the ground truth cannot be obtained: the network needs
training data, which in this case would be pairs of images of a sample stained in
two different techniques. We overcome this problem by using the images of
consecutive slices that are stained using the two distinct techniques, screening
for morphological similarity by comparing their density components in the HSD
color space. We demonstrate the effectiveness of the method in the case of
converting hematoxylin and eosin-stained images into Masson’s trichrome stained
images.
@InProceedings{FujitaniMVA2019,
author = {Masayuki Fujitani and Yoshihiko Mochizuki and Satoshi Iizuka and Edgar Simo-Serra and Hirokazu Kobayashi and Chika Iwamoto and Kenoki Ohuchida and Makoto Hashizume and Hidekata Hontani and Hiroshi Ishikawa},
title = {{Re-staining Pathology Images by FCNN}},
booktitle = "International Conference on Machine Vision Applications (MVA, Oral)",
year = 2019,
}
2018

We address the problem of automatic photo enhancement, in which the challenge is
to determine the optimal enhancement for a given photo according to its content.
For this purpose, we train a convolutional neural network to predict the best
enhancement for given picture. While such machine learning techniques have shown
great promise in photo enhancement, there are some limitations. One is the
problem of interpretability, i.e., that it is not easy for the user to discern
what has been done by a machine. In this work, we leverage existing manual photo
enhancement tools as a black-box model, and predict the enhancement parameters of
that model. Because the tools are designed for human use, the resulting
parameters can be interpreted by their users. Another problem is the difficulty
of obtaining training data. We propose generating supervised training data from
high-quality professional images by randomly sampling realistic de-enhancement
parameters. We show that this approach allows automatic enhancement of
photographs without the need for large manually labelled supervised training
datasets.
@InProceedings{OmiyaSIGGRAPASIABRIEF2018,
author = {Mayu Omiya and Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Learning Photo Enhancement by Black-Box Model Optimization Data Generation}},
booktitle = "SIGGRAPH Asia 2018 Technical Briefs",
year = 2018,
}

We present an interactive approach for inking, which is the process of turning a
pencil rough sketch into a clean line drawing. The approach, which we call the
Smart Inker, consists of several "smart" tools that intuitively react to user
input, while guided by the input rough sketch, to efficiently and naturally
connect lines, erase shading, and fine-tune the line drawing output. Our approach
is data-driven: the tools are based on fully convolutional networks, which we
train to exploit both the user edits and inaccurate rough sketch to produce
accurate line drawings, allowing high-performance interactive editing in
real-time on a variety of challenging rough sketch images. For the training of
the tools, we developed two key techniques: one is the creation of training data
by simulation of vague and quick user edits; the other is a line normalization
based on learning from vector data. These techniques, in combination with our
sketch-specific data augmentation, allow us to train the tools on heterogeneous
data without actual user interaction. We validate our approach with an in-depth
user study, comparing it with professional illustration software, and show that
our approach is able to reduce inking time by a factor of 1.8x while improving
the results of amateur users.
@Article{SimoSerraSIGGRAPH2018,
author = {Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Real-Time Data-Driven Interactive Rough Sketch Inking}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2018,
volume = 37,
number = 4,
}
背景と反射成分の同時推定による画像の映り込み除去
佐藤 良亮,飯塚 里志,シモセラ エドガー,石川 博
第21回画像の認識・理解シンポジウム(MIRU、オーラル) [学生奨励賞], 2018
FCNNを用いた病理画像の染色変換
藤谷 真之,望月 義彦,飯塚 里志,シモセラ エドガー,小林 裕和,岩本 千佳,大内田 研宙,橋爪 誠,本谷 秀堅,石川 博
第21回画像の認識・理解シンポジウム(MIRU、オーラル) [学生奨励賞], 2018
We propose a fully automatic approach to restore aged old line drawings. We
decompose the task into two subtasks: the line extraction subtask, which aims to
extract line fragments and remove the paper texture background, and the
restoration subtask, which fills in possible gaps and deterioration of the lines
to produce a clean line drawing. Our approach is based on a convolutional neural
network that consists of two sub-networks corresponding to the two subtasks. They
are trained as part of a single framework in an end-to-end fashion. We also
introduce a new dataset consisting of manually annotated sketches by Leonardo da
Vinci which, in combination with a synthetic data generation approach, allows
training the network to restore deteriorated line drawings. We evaluate our
method on challenging 500-year-old sketches and compare with existing approaches
with a user study, in which it is found that our approach is preferred 72.7% of
the time.
@Article{SasakiCGI2018,
author = {Sasaki Kazuma and Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa}},
title = {{Learning to Restore Deteriorated Line Drawing}},
journal = "The Visual Computer (Proc. of Computer Graphics International)",
year = {2018},
volume = {34},
pages = {1077--1085},
}

We present an integral framework for training sketch simplification networks that
convert challenging rough sketches into clean line drawings. Our approach
augments a simplification network with a discriminator network, training both
networks jointly so that the discriminator network discerns whether a line
drawing is a real training data or the output of the simplification network,
which in turn tries to fool it. This approach has two major advantages. First,
because the discriminator network learns the structure in line drawings, it
encourages the output sketches of the simplification network to be more similar
in appearance to the training sketches. Second, we can also train the
simplification network with additional unsupervised data, using the discriminator
network as a substitute teacher. Thus, by adding only rough sketches without
simplified line drawings, or only line drawings without the original rough
sketches, we can improve the quality of the sketch simplification. We show how
our framework can be used to train models that significantly outperform the state
of the art in the sketch simplification task, despite using the same architecture
for inference. We additionally present an approach to optimize for a single
image, which improves accuracy at the cost of additional computation time.
Finally, we show that, using the same framework, it is possible to train the
network to perform the inverse problem, i.e., convert simple line sketches into
pencil drawings, which is not possible using the standard mean squared error
loss. We validate our framework with two user tests, where our approach is
preferred to the state of the art in sketch simplification 92.3% of the time and
obtains 1.2 more points on a scale of 1 to 5.
@Article{SimoSerraTOG2018,
author = {Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Mastering Sketching: Adversarial Augmentation for Structured Prediction}},
journal = "Transactions on Graphics (Presented at SIGGRAPH)",
year = 2018,
volume = 37,
number = 1,
}
2017

Content-aware image resizing aims to reduce the size of an image without touching
important objects and regions. In seam carving, this is done by assessing the
importance of each pixel by an energy function and repeatedly removing a string
of pixels avoiding pixels with high energy. However, there is no single energy
function that is best for all images: the optimal energy function is itself a
function of the image. In this paper, we present a method for predicting the
quality of the results of resizing an image with different energy functions, so
as to select the energy best suited for that particular image. We formulate the
selection as a classification problem; i.e., we 'classify' the input into the
class of images for which one of the energies works best. The standard approach
would be to use a CNN for the classification. However, the existence of a fully
connected layer forces us to resize the input to a fixed size, which obliterates
useful information, especially lower-level features that more closely relate to
the energies used for seam carving. Instead, we extract a feature from internal
convolutional layers, which results in a fixed-length vector regardless of the
input size, making it amenable to classification with a Support Vector Machine.
This formulation of the algorithm selection as a classification problem can be
used whenever there are multiple approaches for a specific image processing task.
We validate our approach with a user study, where our method outperforms recent
seam carving approaches.
@InProceedings{SasakiACPR2017,
author = {Kazuma Sasaki and Yuya Nagahama and Zheng Ze and Satoshi Iizuka and Edgar Simo-Serra and Yoshihiko Mochizuki and Hiroshi Ishikawa},
title = {{Adaptive Energy Selection For Content-Aware Image Resizing}},
booktitle = "Proceedings of the Asian Conference on Pattern Recognition (ACPR)",
year = 2017,
}

In this work, we perform an experimental analysis of the differences of both how
humans and machines see and distinguish fashion styles. For this purpose, we
propose an expert-curated new dataset for fashion style prediction, which
consists of 14 different fashion styles each with roughly 1,000 images of worn
outfits. The dataset, with a total of 13,126 images, captures the diversity and
complexity of modern fashion styles. We perform an extensive analysis of the
dataset by benchmarking a wide variety of modern classification networks, and
also perform an in-depth user study with both fashion-savvy and fashion-naive
users. Our results indicate that, although classification networks are able to
outperform naive users, they are still far from the performance of savvy users,
for which it is important to not only consider texture and color, but subtle
differences in the combination of garments.
@InProceedings{TakagiICCVW2017,
author = {Moeko Takagi and Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{What Makes a Style: Experimental Analysis of Fashion Prediction}},
booktitle = "Proceedings of the International Conference on Computer Vision Workshops (ICCVW)",
year = 2017,
}

We present an approach to detect the main product in fashion images by exploiting
the textual metadata associated with each image. Our approach is based on a
Convolutional Neural Network and learns a joint embedding of object proposals and
textual metadata to predict the main product in the image. We additionally use
several complementary classification and overlap losses in order to improve
training stability and performance. Our tests on a large-scale dataset taken from
eight e-commerce sites show that our approach outperforms strong baselines and is
able to accurately detect the main product in a wide diversity of challenging
fashion images.
@InProceedings{RubioICCVW2017,
author = {Antonio Rubio and Longlong Yu and Edgar Simo-Serra and Francesc Moreno-Noguer},
title = {{Multi-Modal Embedding for Main Product Detection in Fashion}},
booktitle = "Proceedings of the International Conference on Computer Vision Workshops (ICCVW)",
year = 2017,
}

We tackle the problem of multi-label classification of fashion images from noisy
data using minimal human supervision. We present a new dataset of full body
poses, each with a set of 66 binary labels corresponding to information about the
garments worn in the image and obtained in an automatic manner. As the
automatically collected labels contain significant noise, for a small subset of
the data, we manually correct the labels, using these correct labels for further
training and evaluating the model. We build upon a recent approach that both
cleans the noisy labels while learning to classify, and show simple changes that
can significantly improve the performance.
@InProceedings{InoueICCVW2017,
author = {Naoto Inoue and Edgar Simo-Serra and Toshihiko Yamasaki and Hiroshi Ishikawa},
title = {{Multi-Label Fashion Image Classification with Minimal Human Supervision}},
booktitle = "Proceedings of the International Conference on Computer Vision Workshops (ICCVW)",
year = 2017,
}

Finding a product in the fashion world can be a daunting task. Everyday,
e-commerce sites are updating with thousands of images and their associated
metadata (textual information), deepening the problem, akin to finding a needle
in a haystack. In this paper, we leverage both the images and textual metadata
and propose a joint multi-modal embedding that maps both the text and images into
a common latent space. Distances in the latent space correspond to similarity
between products, allowing us to effectively perform retrieval in this latent
space, which is both efficient and accurate. We train this embedding using
large-scale real world e-commerce data by both minimizing the similarity between
related products and using auxiliary classification networks to that encourage
the embedding to have semantic meaning. We compare against existing approaches
and show significant improvements in retrieval tasks on a large-scale e-commerce
dataset. We also provide an analysis of the different metadata.
@InProceedings{RubioICIP2017,
author = {Antonio Rubio and Longlong Yu and Edgar Simo-Serra and Francesc Moreno-Noguer},
title = {{Multi-Modal Joint Embedding for Fashion Product Retrieval}},
booktitle = "International Conference on Image Processing (ICIP)",
year = 2017,
}
再帰構造を用いた全層畳み込みニューラルネットワークによる航空写真における建物のセグメンテーション
高橋 宏輝,飯塚 里志,シモセラ エドガー,石川 博
第20回画像の認識・理解シンポジウム(MIRU、オーラル) [学生奨励賞], 2017

Globally and Locally Consistent Image Completion
Satoshi Iizuka, Edgar Simo-Serra, Hiroshi Ishikawa
ACM Transactions on Graphics (SIGGRAPH), 2017
We present a novel approach for image completion that results in images that are
both locally and globally consistent. With a fully-convolutional neural network,
we can complete images of arbitrary resolutions by filling-in missing regions of
any shape. To train this image completion network to be consistent, we use global
and local context discriminators that are trained to distinguish real images from
completed ones. The global discriminator looks at the entire image to assess if
it is coherent as a whole, while the local discriminator looks only at a small
area centered at the completed region to ensure the local consistency of the
generated patches. The image completion network is then trained to fool the both
context discriminator networks, which requires it to generate images that are
indistinguishable from real ones with regard to overall consistency as well as in
details. We show that our approach can be used to complete a wide variety of
scenes. Furthermore, in contrast with the patch-based approaches such as
PatchMatch, our approach can generate fragments that do not appear elsewhere in
the image, which allows us to naturally complete the images of objects with
familiar and highly specific structures, such as faces.
@Article{IizukaSIGGRAPH2017,
author = {Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa},
title = {{Globally and Locally Consistent Image Completion}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2017,
volume = 36,
number = 4,
}
We propose a novel data-driven approach for automatically detecting and
completing gaps in line drawings with a Convolutional Neural Network. In the case
of existing inpainting approaches for natural images, masks indicating the
missing regions are generally required as input. Here, we show that line drawings
have enough structures that can be learned by the CNN to allow automatic
detection and completion of the gaps without any such input. Thus, our method can
find the gaps in line drawings and complete them without user interaction.
Furthermore, the completion realistically conserves thickness and curvature of
the line segments. All the necessary heuristics for such realistic line
completion are learned naturally from a dataset of line drawings, where various
patterns of line completion are generated on the fly as training pairs to improve
the model generalization. We evaluate our method qualitatively on a diverse set
of challenging line drawings and also provide quantitative results with a user
study, where it significantly outperforms the state of the art.
@InProceedings{SasakiCVPR2017,
author = {Kazuma Sasaki Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa},
title = {{Joint Gap Detection and Inpainting of Line Drawings}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2017,
}
回帰分析にもとづく補正モデルを用いた写真の自動補正
近江谷 真由,シモセラ エドガー,飯塚 里志,石川 博
Visual Computing / グラフィクスとCAD 合同シンポジウム(オーラル), 2017
ディープマリオ
北川 竜太郎,シモセラ エドガー,飯塚 里志,望月 義彦,石川 博
Visual Computing / グラフィクスとCAD 合同シンポジウム(オーラル), 2017
Banknotes generally have different designs according to their denominations.
Thus, if characteristics of each design can be recognized, they can be used for
sorting banknotes according to denominations. Portrait in banknotes is one such
characteristic that can be used for classification. A sorting system for
banknotes can be designed that recognizes portraits in each banknote and sort it
accordingly. In this paper, our aim is to automate the configuration of such a
sorting system by automatically detect portraits in sample banknotes, so that it
can be quickly deployed in a new target country. We use Convolutional Neural
Networks to detect portraits in completely new set of banknotes robust to
variation in the ways they are shown, such as the size and the orientation of the
face.
@InProceedings{KitagawaMVA2017,
author = {Ryutaro Kitagawa and Yoshihiko Mochizuki and Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Matsuki and Naotake Natori and Hiroshi Ishikawa},
title = {{Banknote Portrait Detection Using Convolutional Neural Network}},
booktitle = "International Conference on Machine Vision Applications (MVA)",
year = 2017,
}
Finding a product in the fashion world can be a daunting task. Everyday,
e-commerce sites are updating with thousands of images and their associated
metadata (textual information), deepening the problem. In this paper, we leverage
both the images and textual metadata and propose a joint multi-modal embedding
that maps both the text and images into a common latent space. Distances in the
latent space correspond to similarity between products, allowing us to
effectively perform retrieval in this latent space. We compare against existing
approaches and show significant improvements in retrieval tasks on a large-scale
e-commerce dataset
@InProceedings{RubioVL2017,
author = {Antonio Rubio and Longlong Yu and Edgar Simo-Serra and Francesc Moreno-Noguer},
title = {{Multi-Modal Fashion Product Retrieval}},
booktitle = "The 6th Workshop on Vision and Language (VL)",
year = 2017,
}
2016

We propose a new superpixel algorithm based on exploiting the boundary
information of an image, as objects in images can generally be described by their
boundaries. Our proposed approach initially estimates the boundaries and uses
them to place superpixel seeds in the areas in which they are more dense.
Afterwards, we minimize an energy function in order to expand the seeds into full
superpixels. In addition to standard terms such as color consistency and
compactness, we propose using the geodesic distance which concentrates small
superpixels in regions of the image with more information, while letting larger
superpixels cover more homogeneous regions. By both improving the initialization
using the boundaries and coherency of the superpixels with geodesic distances, we
are able to maintain the coherency of the image structure with fewer superpixels
than other approaches. We show the resulting algorithm to yield smaller Variation
of Information metrics in seven different datasets while maintaining
Undersegmentation Error values similar to the state-of-the-art methods.
@InProceedings{RubioICPR2016,
author = {Antonio Rubio and Longlong Yu and Edgar Simo-Serra and Francesc Moreno-Noguer},
title = {{BASS: Boundary-Aware Superpixel Segmentation}},
booktitle = "Proceedings of the International Conference on Pattern Recognition (ICPR)",
year = 2016,
}

Detection by Classification of Buildings in Multispectral Satellite
Imagery
Tomohiro Ishii, Edgar Simo-Serra, Satoshi Iizuka, Yoshihiko Mochizuki, Akihiro
Sugimoto, Hiroshi Ishikawa, Ryosuke Nakamura
International Conference on Pattern Recognition (ICPR), 2016
We present an approach for the detection of buildings in multispectral satellite
images. Unlike 3-channel RGB images, satellite imagery contains additional
channels corresponding to different wavelengths. Approaches that do not use all
channels are unable to fully exploit these images for optimal performance.
Furthermore, care must be taken due to the large bias in classes, e.g., most of
the Earth is covered in water and thus it will be dominant in the images. Our
approach consists of training a Convolutional Neural Network (CNN) from scratch
to classify multispectral image patches taken by satellites as whether or not
they belong to a class of buildings. We then adapt the classification network to
detection by converting the fully-connected layers of the network to
convolutional layers, which allows the network to process images of any
resolution. The dataset bias is compensated by subsampling negatives and tuning
the detection threshold for optimal performance. We have constructed a new
dataset using images from the Landsat 8 satellite for detecting solar power
plants and show our approach is able to significantly outperform the
state-of-the-art. Furthermore, we provide an in-depth evaluation of the seven
different spectral bands provided by the satellite images and show it is critical
to combine them to obtain good results.
@InProceedings{IshiiICPR2016,
author = {Tomohiro Ishii and Edgar Simo-Serra and Satoshi Iizuka and Yoshihiko Mochizuki and Akihiro Sugimoto and Hiroshi Ishikawa and Ryosuke Nakamura},
title = {{Detection by Classification of Buildings in Multispectral Satellite Imagery}},
booktitle = "Proceedings of the International Conference on Pattern Recognition (ICPR)",
year = 2016,
}
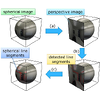
We propose a method to reconstruct a simple room from a single spherical image,
i.e., to identify structural planes that form the ceiling, the floor, and the
walls. A spherical image records the light that falls on a single viewpoint from
all directions. Because there is no need to correlate geometrical information
from multiple images, it facilitates the robust reconstruction of precise
structure of the room. In our method, we first detect line segments in the image,
which we then classify into those that form the boundaries of the structural
planes and those that do not. The classification is a large combinatorial
problem, which we solve with graph cuts as a minimization problem of a
higher-order energy that combines the various measures of likelihood that one,
two, or three line segments are part of the boundary. Finally, we estimate the
planes that constitute the room from the line segments classified as residing on
the boundaries. We evaluate the proposed method on synthetic and real images.
@InProceedings{FukanoICPR2016,
author = {Kosuke Fukano and Yoshihiko Mochizuki and Edgar Simo-Serra and Satoshi Iizuka and Akihiro Sugimoto and Hiroshi Ishikawa},
title = {{Room Reconstruction from a Single Spherical Image by Higher-order Energy Minimization}},
booktitle = "Proceedings of the International Conference on Pattern Recognition (ICPR)",
year = 2016,
}

We present a novel approach for learning a finite mixture model on a Riemannian
manifold in which Euclidean metrics are not applicable and one needs to resort to
geodesic distances consistent with the manifold geometry. For this purpose, we
draw inspiration on a variant of the expectation-maximization algorithm, that
uses a minimum message length criterion to automatically estimate the optimal
number of components from multivariate data lying on an Euclidean space. In order
to use this approach on Riemannian manifolds, we propose a formulation in which
each component is defined on a different tangent space, thus avoiding the
problems associated with the loss of accuracy produced when linearizing the
manifold with a single tangent space. Our approach can be applied to any type of
manifold for which it is possible to estimate its tangent space. Additionally, we
consider using shrinkage covariance estimation to improve the robustness of the
method, especially when dealing with very sparsely distributed samples. We
evaluate the approach on a number of situations, going from data clustering on
manifolds to combining pose and kinematics of articulated bodies for 3D human
pose tracking. In all cases, we demonstrate remarkable improvement compared to
several chosen baselines.
@Article{SimoSerraIJCV2016,
author = {Edgar Simo-Serra and Carme Torras and Francesc Moreno Noguer},
title = {{3D Human Pose Tracking Priors using Geodesic Mixture Models}},
journal = {International Journal of Computer Vision (IJCV)},
volume = {122},
number = {2},
pages = {388--408},
year = 2016,
}

In this paper, we present a novel technique to simplify sketch drawings based on
learning a series of convolution operators. In contrast to existing approaches
that require vector images as input, we allow the more general and challenging
input of rough raster sketches such as those obtained from scanning pencil
sketches. We convert the rough sketch into a simplified version which is then
amendable for vectorization. This is all done in a fully automatic way without
user intervention. Our model consists of a fully convolutional neural network
which, unlike most existing convolutional neural networks, is able to process
images of any dimensions and aspect ratio as input, and outputs a simplified
sketch which has the same dimensions as the input image. In order to teach our
model to simplify, we present a new dataset of pairs of rough and simplified
sketch drawings. By leveraging convolution operators in combination with
efficient use of our proposed dataset, we are able to train our sketch
simplification model. Our approach naturally overcomes the limitations of
existing methods, e.g., vector images as input and long computation time; and we
show that meaningful simplifications can be obtained for many different test
cases. Finally, we validate our results with a user study in which we greatly
outperform similar approaches and establish the state of the art in sketch
simplification of raster images.
@Article{SimoSerraSIGGRAPH2016,
author = {Edgar Simo-Serra and Satoshi Iizuka and Kazuma Sasaki and Hiroshi Ishikawa},
title = {{Learning to Simplify: Fully Convolutional Networks for Rough Sketch Cleanup}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2016,
volume = 35,
number = 4,
}

Let there be Color!: Joint End-to-end Learning of Global and Local
Image Priors for Automatic Image Colorization with Simultaneous
Classification
Satoshi Iizuka*, Edgar Simo-Serra*, Hiroshi Ishikawa (* equal contribution)
ACM Transactions on Graphics (SIGGRAPH), 2016
We present a novel technique to automatically colorize grayscale images that
combines both global priors and local image features. Based on Convolutional
Neural Networks, our deep network features a fusion layer that allows us to
elegantly merge local information dependent on small image patches with global
priors computed using the entire image. The entire framework, including the
global and local priors as well as the colorization model, is trained in an
end-to-end fashion. Furthermore, our architecture can process images of any
resolution, unlike most existing approaches based on CNN. We leverage an existing
large-scale scene classification database to train our model, exploiting the
class labels of the dataset to more efficiently and discriminatively learn the
global priors. We validate our approach with a user study and compare against the
state of the art, where we show significant improvements. Furthermore, we
demonstrate our method extensively on many different types of images, including
black-and-white photography from over a hundred years ago, and show realistic
colorizations.
@Article{IizukaSIGGRAPH2016,
author = {Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa},
title = {{Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2016,
volume = 35,
number = 4,
}

We propose a novel approach for learning features from weakly-supervised data by
joint ranking and classification. In order to exploit data with weak labels, we
jointly train a feature extraction network with a ranking loss and a
classification network with a cross-entropy loss. We obtain high-quality compact
discriminative features with few parameters, learned on relatively small datasets
without additional annotations. This enables us to tackle tasks with specialized
images not very similar to the more generic ones in existing fully-supervised
datasets. We show that the resulting features in combination with a linear
classifier surpass the state-of-the-art on the Hipster Wars dataset despite using
features only 0.3% of the size. Our proposed features significantly outperform
those obtained from networks trained on ImageNet, despite being 32 times smaller
(128 single-precision floats), trained on noisy and weakly-labeled data, and
using only 1.5% of the number of parameters.
@InProceedings{SimoSerraCVPR2016,
author = {Edgar Simo-Serra and Hiroshi Ishikawa},
title = {{Fashion Style in 128 Floats: Joint Ranking and Classification using Weak Data for Feature Extraction}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2016,
}
Structured Prediction with Output Embeddings for Semantic Image
Annotation
Ariadna Quattoni, Arnau Ramisa, Pranava Swaroop Madhyastha, Edgar Simo-Serra,
Francesc Moreno-Noguer
Conference of the North American Chapter of the Association for
Computational Linguistics: Human Language Technologies (NAACL-HLT, Short),
2016
We address the task of annotating images with semantic tuples. Solving this
problem requires an algorithm which is able to deal with hundreds of classes for
each argument of the tuple. In such contexts, data sparsity becomes a key
challenge, as there will be a large number of classes for which only a few
examples are available. We propose handling this by incorporating feature
representations of both the inputs (images) and outputs (argument classes) into a
factorized log-linear model, and exploiting the flexibility of scoring functions
based on bilinear forms. Experiments show that integrating feature
representations of the outputs in the structured prediction model leads to better
overall predictions. We also conclude that the best output representation is
specific for each type of argument.
@InProceedings{QuattoniARXIV2016,
author = {Ariadna Quattoni and Arnau Ramisa and Pranava Swaroop Madhyastha and Edgar Simo-Serra and Francesc Moreno-Noguer},
title = {{Structured Prediction with Output Embeddings for Semantic Image Annotation}},
booktitle = "Proocedings of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT)",
year = 2016,
}
2015
Discriminative Learning of Deep Convolutional Feature Point
Descriptors
Edgar Simo-Serra*, Eduard Trulls*, Luis Ferraz, Iasonas Kokkinos, Pascal Fua,
Francesc Moreno-Noguer (* equal contribution)
International Conference on Computer Vision (ICCV), 2015
Deep learning has revolutionalized image-level tasks, e.g. image classification,
but patch-level tasks, e.g. point correspondence still rely on hand-crafted
features, such as SIFT. In this paper we use Convolutional Neural Networks (CNNs)
to learn discriminant patch representations and in particular train a Siamese
network with pairs of (non-)corresponding patches. We deal with the large number
of non-corresponding patches with the combination of stochastic sampling of the
training set and an aggressive mining strategy biased towards patches that are
hard to classify. Our models are fully convolutional, efficient to compute and
amenable to modern GPUs, and can be used as a drop-in replacement for SIFT. We
obtain consistent performance gains over the state of the art, and most
importantly generalize well against scaling and rotation, perspective
transformation, non-rigid deformation, and illumination changes.
@InProceedings{SimoSerraICCV2015,
author = {Edgar Simo-Serra and Eduard Trulls and Luis Ferraz and Iasonas Kokkinos and Pascal Fua and Francesc Moreno-Noguer},
title = {{Discriminative Learning of Deep Convolutional Feature Point Descriptors}},
booktitle = "Proceedings of the International Conference on Computer Vision (ICCV)",
year = 2015,
}

Understanding humans from photographs has always been a fundamental goal of
computer vision. Early works focused on simple tasks such as detecting the
location of individuals by means of bounding boxes. As the field progressed,
harder and more higher level tasks have been undertaken. For example, from human
detection came the 2D and 3D human pose estimation in which the task consisted of
identifying the location in the image or space of all different body parts, e.g.,
head, torso, knees, arms, etc. Human attributes also became a great source of
interest as they allow recognizing individuals and other properties such as
gender or age. Later, the attention turned to the recognition of the action being
performed. This, in general, relies on the previous works on pose estimation and
attribute classification. Currently, even higher level tasks are being conducted
such as predicting the motivations of human behaviour or identifying the
fashionability of an individual from a photograph. In this thesis we have
developed a hierarchy of tools that cover all these range of problems, from low
level feature point descriptors to high level fashion-aware conditional random
fields models, all with the objective of understanding humans from monocular RGB
images. In order to build these high level models it is paramount to have a
battery of robust and reliable low and mid level cues. Along these lines, we have
proposed two low-level keypoint descriptors: one based on the theory of the heat
diffusion on images, and the other that uses a convolutional neural network to
learn discriminative image patch representations. We also introduce distinct
low-level generative models for representing human pose: in particular we present
a discrete model based on a directed acyclic graph and a continuous model that
consists of poses clustered on a Riemannian manifold. As mid level cues we
propose two 3D human pose estimation algorithms: one that estimates the 3D pose
given a noisy 2D estimation, and an approach that simultaneously estimates both
the 2D and 3D pose. Finally, we formulate higher level models built upon low and
mid level cues for understanding humans from single images. Concretely, we focus
on two different tasks in the context of fashion: semantic segmentation of
clothing, and predicting the fashionability from images with METAData to
ultimately provide fashion advice to the user. In summary, to robustly extract
knowledge from images with the presence of humans it is necessary to build high
level models that integrate low and mid level cues. In general, using and
understanding strong features is critical for obtaining reliable performance. The
main contribution of this thesis is in proposing a variety of low, mid and high
level algorithms for human-centric images that can be integrated into higher
level models for comprehending humans from photographs, as well as tackling novel
fashion-oriented problems.
@phdthesis{SimoSerraPHD2015,
author = {Edgar Simo-Serra},
title = {{Understanding Human-Centric Images: From Geometry to Fashion}},
school = "BarcelonaTech (UPC)",
year = 2015,
}
In this paper, we analyze the fashion of clothing of a large social website. Our
goal is to learn and predict how fashionable a person looks on a photograph and
suggest subtle improvements the user could make to improve her/his appeal. We
propose a Conditional Random Field model that jointly reasons about several
fashionability factors such as the type of outfit and garments the user is
wearing, the type of the user, the photograph's setting (e.g., the scenery behind
the user), and the fashionability score. Importantly, our model is able to give
rich feedback back to the user, conveying which garments or even scenery she/he
should change in order to improve fashionability. We demonstrate that our joint
approach significantly outperforms a variety of intelligent baselines. We
additionally collected a novel heterogeneous dataset with 144,169 user posts
containing diverse image, textual and meta information which can be exploited for
our task. We also provide a detailed analysis of the data, showing different
outfit trends and fashionability scores across the globe and across a span of 6
years.
@InProceedings{SimoSerraCVPR2015,
author = {Edgar Simo-Serra and Sanja Fidler and Francesc Moreno-Noguer and Raquel Urtasun},
title = {{Neuroaesthetics in Fashion: Modeling the Perception of Fashionability}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2015,
}

We propose a robust and efficient method to estimate the pose of a camera with
respect to complex 3D textured models of the environment that can potentially
contain more than 100,000 points. To tackle this problem we follow a top down
approach where we combine high-level deep network classifiers with low level
geometric approaches to come up with a solution that is fast, robust and
accurate. Given an input image, we initially use a pre-trained deep network to
compute a rough estimation of the camera pose. This initial estimate constrains
the number of 3D model points that can be seen from the camera viewpoint. We then
establish 3D-to-2D correspondences between these potentially visible points of
the model and the 2D detected image features. Accurate pose estimation is finally
obtained from the 2D-to-3D correspondences using a novel PnP algorithm that
rejects outliers without the need to use a RANSAC strategy, and which is between
10 and 100 times faster than other methods that use it. Two real experiments
dealing with very large and complex 3D models demonstrate the effectiveness of
the approach.
@InProceedings{RubioICRA2015,
author = {Antonio Rubio and Michael Villamizar and Luis Ferraz and Adri\'an Pe\~nate-S\'anchez and Arnau Ramisa and Edgar Simo-Serra and Alberto Sanfeliu and Francesc Moreno-Noguer},
title = {{Efficient Monocular Pose Estimation for Complex 3D Models}},
booktitle = "Proceedings of the International Conference in Robotics and Automation (ICRA)",
year = 2015,
}

We propose a novel kinematic prior for 3D human pose tracking that allows
predicting the position in subsequent frames given the current position. We first
define a Riemannian manifold that models the pose and extend it with its Lie
algebra to also be able to represent the kinematics. We then learn a joint
Gaussian mixture model of both the human pose and the kinematics on this
manifold. Finally by conditioning the kinematics on the pose we are able to
obtain a distribution of poses for subsequent frames that which can be used as a
reliable prior in 3D human pose tracking. Our model scales well to large amounts
of data and can be sampled at over 100,000 samples/second. We show it outperforms
the widely used Gaussian diffusion model on the challenging Human3.6M dataset.
@InProceedings{SimoSerraMVA2015,
author = {Edgar Simo-Serra and Carme Torras and Francesc Moreno-Noguer},
title = {{Lie Algebra-Based Kinematic Prior for 3D Human Pose Tracking}},
booktitle = "International Conference on Machine Vision Applications (MVA)",
year = 2015,
}

Recent advances in 3D shape analysis and recognition have shown that heat
diffusion theory can be effectively used to describe local features of deforming
and scaling surfaces. In this paper, we show how this description can be used to
characterize 2D image patches, and introduce DaLI, a novel feature point
descriptor with high resilience to non-rigid image transformations and
illumination changes. In order to build the descriptor, 2D image patches are
initially treated as 3D surfaces. Patches are then described in terms of a heat
kernel signature, which captures both local and global information, and shows a
high degree of invariance to non-linear image warps. In addition, by further
applying a logarithmic sampling and a Fourier transform, invariance to
photometric changes is achieved. Finally, the descriptor is compacted by mapping
it onto a low dimensional subspace computed using Principal Component Analysis,
allowing for an efficient matching. A thorough experimental validation
demonstrates that DaLI is significantly more discriminative and robust to
illuminations changes and image transformations than state of the art
descriptors, even those specifically designed to describe non-rigid deformations.
@Article{SimoSerraIJCV2015,
author = {Edgar Simo-Serra and Carme Torras and Francesc Moreno Noguer},
title = {{DaLI: Deformation and Light Invariant Descriptor}},
journal = {International Journal of Computer Vision (IJCV)},
volume = {115},
number = {2},
pages = {136--154},
year = 2015,
}
2014

In this paper we tackle the problem of semantic segmentation of clothing. We
frame the problem as the one of inference in a pose-aware Markov random field
which exploits appearance, figure/ground segmentation, shape and location priors
for each garment as well as similarities between segments and symmetries between
different human body parts. We demonstrate the effectiveness of our approach in
the fashionista dataset and show that we can obtain a significant improvement
over the state-of-the-art.
@InProceedings{SimoSerraACCV2014,
author = {Edgar Simo-Serra and Sanja Fidler and Francesc Moreno-Noguer and Raquel Urtasun},
title = {{A High Performance CRF Model for Clothes Parsing}},
booktitle = "Proceedings of the Asian Conference on Computer Vision (ACCV)",
year = 2014,
}

We present a novel approach for learning a finite mixture model on a Riemannian
manifold in which Euclidean metrics are not applicable and one needs to resort to
geodesic distances consistent with the manifold geometry. For this purpose, we
draw inspiration on a variant of the expectation-maximization algorithm, that
uses a minimum message length criterion to automatically estimate the optimal
number of components from multivariate data lying on an Euclidean space. In order
to use this approach on Riemannian manifolds, we propose a formulation in which
each component is defined on a different tangent space, thus avoiding the
problems associated with the loss of accuracy produced when linearizing the
manifold with a single tangent space. Our approach can be applied to any type of
manifold for which it is possible to estimate its tangent space. In particular,
we show results on synthetic examples of a sphere and a quadric surface and on a
large and complex dataset of human poses, where the proposed model is used as a
regression tool for hypothesizing the geometry of occluded parts of the body.
@InProceedings{SimoSerraBMVC2014,
author = {Edgar Simo-Serra and Carme Torras and Francesc Moreno-Noguer},
title = {{Geodesic Finite Mixture Models}},
booktitle = "Proceedings of the British Machine Vision Conference (BMVC)",
year = 2014,
}

This paper presents a methodology for the description and finite-position
dimensional synthesis of articulated systems with multiple end-effectors. The
articulated system is represented as a rooted tree graph. Graph and dimensional
synthesis theories are applied to determine when exact finite-position synthesis
can be performed on the tree structures by considering the motion for all the
possible subgraphs. Several examples of tree topologies are presented and
synthesized. This theory has an immediate application on the design of novel
multi-fingered hands.
@Article{SimoSerraMAMT2014,
author = {Edgar Simo-Serra and Alba Perez-Gracia},
title = {{Kinematic Synthesis using Tree Topologies}},
journal = {Mechanism and Machine Theory},
volume = {72},
pages = {94--113},
year = 2014,
}
2013

We introduce a novel approach to automatically recover 3D human pose from a
single image. Most previous work follows a pipelined approach: initially, a set
of 2D features such as edges, joints or silhouettes are detected in the image,
and then these observations are used to infer the 3D pose. Solving these two
problems separately may lead to erroneous 3D poses when the feature detector has
performed poorly. In this paper, we address this issue by jointly solving both
the 2D detection and the 3D inference problems. For this purpose, we propose a
Bayesian framework that integrates a generative model based on latent variables
and discriminative 2D part detectors based on HOGs, and perform inference using
evolutionary algorithms. Real experimentation demonstrates competitive results,
and the ability of our methodology to provide accurate 2D and 3D pose estimations
even when the 2D detectors are inaccurate.
@InProceedings{SimoSerraCVPR2013,
author = {Edgar Simo-Serra and Ariadna Quattoni and Carme Torras and Francesc Moreno-Noguer},
title = {{A Joint Model for 2D and 3D Pose Estimation from a Single Image}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2013,
}
2012
Kinematic Synthesis of Multi-Fingered Robotic Hands for Finite and
Infinitesimal Tasks
Edgar Simo-Serra, Alba Perez-Gracia, Hyosang Moon, Nina Robson
Advances in Robot Kinematics (ARK), 2012
In this paper we present a novel method of designing multi-fingered robotic hands
using tasks composed of both finite and infinitesimal motion. The method is based
on representing the robotic hands as a kinematic chain with a tree topology. We
represent finite motion using Clifford algebra and infinitesimal motion using Lie
algebra to perform finite dimensional kinematic synthesis of the multi-fingered
mechanism. This allows tasks to be defined not only by displacements, but also by
the velocity and acceleration at different positions for the design of robotic
hands. An example task is provided using an experimental motion capture system
and we present the design of a robotic hand for the task using a hybrid Genetic
Algorithm/Levenberg-Marquadt solver.
@InProceedings{SimoSerraARK2012,
author = {Edgar Simo-Serra and Alba Perez-Gracia and Hyosang Moon and Nina Robson},
title = {{Kinematic Synthesis of Multi-Fingered Robotic Hands for Finite and Infinitesimal Tasks}},
booktitle = "Advances in Robot Kinematics (ARK)",
year = 2012,
}
Markerless 3D human pose detection from a single image is a severely
underconstrained problem in which different 3D poses can have very similar image
projections. In order to handle this ambiguity, current approaches rely on prior
shape models whose parameters are estimated by minimizing image-based objective
functions that require 2D features to be accurately detected in the input images.
Unfortunately, although current 2D part detectors algorithms have shown promising
results, their accuracy is not yet sufficiently high to subsequently infer the 3D
human pose in a robust and unambiguous manner. We introduce a novel approach for
estimating 3D human pose even when observations are noisy. We propose a
stochastic sampling strategy to propagate the noise from the image plane to the
shape space. This provides a set of ambiguous 3D shapes, which are virtually
undistinguishable using image-based information alone. Disambiguation is then
achieved by imposing kinematic constraints that guarantee the resulting pose
resembles a 3D human shape. We validate our approach on a variety of situations
in which state-of-the-art 2D detectors yield either inaccurate estimations or
partly miss some of the body parts.
@InProceedings{SimoSerraCVPR2012,
author = {Edgar Simo-Serra and Arnau Ramisa and Guillem Aleny\`a and Carme Torras and Francesc Moreno-Noguer},
title = {{Single Image 3D Human Pose Estimation from Noisy Observations}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2012,
}
2011
Design of Non-Anthropomorphic Robotic Hands for Anthropomorphic
Tasks
Edgar Simo-Serra, Francesc Moreno-Noguer, Alba Perez-Gracia
ASME International Design Engineering Technical Conferences (IDETC),
2011
In this paper, we explore the idea of designing non-anthropomorphic,
multi-fingered robotic hands for tasks that replicate the motion of the human
hand. Taking as input data rigid-body trajectories for the five fingertips, we
develop a method to perform dimensional synthesis for a kinematic chain with a
tree structure, with three common joints and five branches. We state the forward
kinematics equations of relative displacements for each serial chain expressed as
dual quaternions, and solve for up to five chains simultaneously to reach a
number of poses along the hand trajectory using a hybrid global numerical solver
that integrates a genetic algorithm and a Levenberg-Marquardt local optimizer.
Although the number of candidate solutions in this problem is very high, the use
of the genetic algorithm lets us to perform an exhaustive exploration of the
solution space and retain a subset of them. We then can choose some of the
solutions based on the specific task to perform. Note that these designs could
match the task exactly while having a finger design radically different from that
of the human hand.
@InProceedings{SimoSerraIDETC2011,
author = {Edgar Simo-Serra and Francesc Moreno-Noguer and Alba Perez-Gracia},
title = {{Design of Non-Anthropomorphic Robotic Hands for Anthropomorphic Tasks}},
booktitle = "Proceedings of the 2011 ASME International Design Engineering Technical Conferences",
year = 2011,
}
Biotechnology is a science that is growing rapidly. The objective of this project
is to advance in the field. Specifically it aims to study applications of
kinematics in the field of human-machine interfaces namely exoskeleton and
prosthesis designs for the human hand. The methodology used in this project
consists of three phases. First a theoretical model of the hand kinematics is
defined from medical literature. This is done by synthesizing the hand into its
simplified parameters to define a robotic model. The adjustment of the
theoretical model to a hand is then done by capturing the movement using computer
vision. This is done by using markers on each nail to be able to estimate their
poses which consist of their spatial orientation and position. This sequence
permits estimating the movement of the entire hand. Dimensional kinematic
synthesis is finally applied to adapt the theoretical model to the dataset
provided by computer vision. This is done by defining the equations of the
movement of the theoretical hand model and is then solved by a numerical solver.
This allows the creation of a personalized hand model that can then be used for
the study of correspondences between electromyography and the movements of the
hand. In conclusion, this project has designed a robust algorithm for the
tracking and estimation of the poses of the nails of the hand. It has also
defined the movement equations and created an application to solve them. This has
led to the finding of many non-anthropomorphic models that can be of use in the
design of exoskeletons.
@mastersthesis{SimoSerraPFC2011,
author = {Edgar Simo-Serra},
title = {{Kinematic Model of the Hand using Computer Vision}},
school = "BarcelonaTech (UPC)",
type = "Degree Thesis",
year = 2011,
}