Research
-
Smart Inker

We present an interactive approach for inking, which is the process of turning a pencil rough sketch into a clean line drawing. The approach, which we call the Smart Inker, consists of several “smart” tools that intuitively react to user input, while guided by the input rough sketch, to efficiently and naturally connect lines, erase shading, and fine-tune the line drawing output. Our approach is data-driven: the tools are based on fully convolutional networks, which we train to exploit both the user edits and inaccurate rough sketch to produce accurate line drawings, allowing high-performance interactive editing in real-time on a variety of challenging rough sketch images. For the training of the tools, we developed two key techniques: one is the creation of training data by simulation of vague and quick user edits; the other is a line normalization based on learning from vector data. These techniques, in combination with our sketch-specific data augmentation, allow us to train the tools on heterogeneous data without actual user interaction. We validate our approach with an in-depth user study, comparing it with professional illustration software, and show that our approach is able to reduce inking time by a factor of 1.8x while improving the results of amateur users.
Deep Sketch Vectorization via Implicit Surface ExtractionChuan Yan, Yong Li, Deepali Aneja, Matthew Fisher, Edgar Simo-Serra, Yotam GingoldACM Transactions on Graphics (SIGGRAPH), 2024Real-Time Data-Driven Interactive Rough Sketch InkingEdgar Simo-Serra, Satoshi Iizuka, Hiroshi IshikawaACM Transactions on Graphics (SIGGRAPH), 2018 -
Mastering Sketching
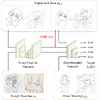
We present an integral framework for training sketch simplification networks that convert challenging rough sketches into clean line drawings. Our approach augments a simplification network with a discriminator network, training both networks jointly so that the discriminator network discerns whether a line drawing is a real training data or the output of the simplification network, which in turn tries to fool it. This approach has two major advantages: first, because the discriminator network learns the structure in line drawings, it encourages the output sketches of the simplification network to be more similar in appearance to the training sketches. Second, we can also train the networks with additional unsupervised data: by adding rough sketches and line drawings that are not corresponding to each other, we can improve the quality of the sketch simplification. Thanks to a difference in the architecture, our approach has advantages over similar adversarial training approaches in stability of training and the aforementioned ability to utilize unsupervised training data. We show how our framework can be used to train models that significantly outperform the state of the art in the sketch simplification task, despite using the same architecture for inference. We additionally present an approach to optimize for a single image, which improves accuracy at the cost of additional computation time. Finally, we show that, using the same framework, it is possible to train the network to perform the inverse problem, i.e., convert simple line sketches into pencil drawings, which is not possible using the standard mean squared error loss.
Mastering Sketching: Adversarial Augmentation for Structured PredictionEdgar Simo-Serra*, Satoshi Iizuka*, Hiroshi Ishikawa (* equal contribution)ACM Transactions on Graphics (Presented at SIGGRAPH), 2018 -
Globally and Locally Consistent Image Completion

We present a novel approach for image completion that results in images that are both locally and globally consistent. With a fully-convolutional neural network, we can complete images of arbitrary resolutions by filling-in missing regions of any shape. To train this image completion network to be consistent, we use global and local context discriminators that are trained to distinguish real images from completed ones. The global discriminator looks at the entire image to assess if it is coherent as a whole, while the local discriminator looks only at a small area centered at the completed region to ensure the local consistency of the generated patches. The image completion network is then trained to fool the both context discriminator networks, which requires it to generate images that are indistinguishable from real ones with regard to overall consistency as well as in details. We show that our approach can be used to complete a wide variety of scenes. Furthermore, in contrast with the patch-based approaches such as PatchMatch, our approach can generate fragments that do not appear elsewhere in the image, which allows us to naturally complete the images of objects with familiar and highly specific structures, such as faces.
Globally and Locally Consistent Image CompletionSatoshi Iizuka, Edgar Simo-Serra, Hiroshi IshikawaACM Transactions on Graphics (SIGGRAPH), 2017 -
Sketch Simplification

We present a novel technique to simplify sketch drawings based on learning a series of convolution operators. In contrast to existing approaches that require vector images as input, we allow the more general and challenging input of rough raster sketches such as those obtained from scanning pencil sketches. We convert the rough sketch into a simplified version which is then amendable for vectorization. This is all done in a fully automatic way without user intervention. Our model consists of a fully convolutional neural network which, unlike most existing convolutional neural networks, is able to process images of any dimensions and aspect ratio as input, and outputs a simplified sketch which has the same dimensions as the input image. In order to teach our model to simplify, we present a new dataset of pairs of rough and simplified sketch drawings. By leveraging convolution operators in combination with efficient use of our proposed dataset, we are able to train our sketch simplification model. Our approach naturally overcomes the limitations of existing methods, e.g., vector images as input and long computation time; and we show that meaningful simplifications can be obtained for many different test cases. Finally, we validate our results with a user study in which we greatly outperform similar approaches and establish the state of the art in sketch simplification of raster images.
Learning to Simplify: Fully Convolutional Networks for Rough Sketch CleanupEdgar Simo-Serra*, Satoshi Iizuka*, Kazuma Sasaki, Hiroshi Ishikawa (* equal contribution)ACM Transactions on Graphics (SIGGRAPH), 2016 -
Colorization of Black and White Images

We present a novel technique to automatically colorize grayscale images that combines both global priors and local image features. Based on Convolutional Neural Networks, our deep network features a fusion layer that allows us to elegantly merge local information dependent on small image patches with global priors computed using the entire image. The entire framework, including the global and local priors as well as the colorization model, is trained in an end-to-end fashion. Furthermore, our architecture can process images of any resolution, unlike most existing approaches based on CNN. We leverage an existing large-scale scene classification database to train our model, exploiting the class labels of the dataset to more efficiently and discriminatively learn the global priors. We validate our approach with a user study and compare against the state of the art, where we show significant improvements. Furthermore, we demonstrate our method extensively on many different types of images, including black-and-white photography from over a hundred years ago, and show realistic colorizations.
Let there be Color!: Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous ClassificationSatoshi Iizuka*, Edgar Simo-Serra*, Hiroshi Ishikawa (* equal contribution)ACM Transactions on Graphics (SIGGRAPH), 2016 -
Fashion Style in 128 Floats

In this work we present an approach for learning features from large amounts of weakly-labelled data. Our approach consists training a convolutional neural network with both a ranking and classification loss jointly. We do this by exploiting user-provided metadata of images on the web. We define a rough concept of similarity between images using this metadata, which allows us to define a ranking loss using this similarity. Combining this ranking loss with a standard classification loss, we are able to learn a compact 128 float representation of fashion style using only noisy user provided tags that outperforms standard features. Furthermore, qualitative analysis shows that our model is able to automatically learn nuances in style.
Fashion Style in 128 Floats: Joint Ranking and Classification using Weak Data for Feature ExtractionEdgar Simo-Serra and Hiroshi IshikawaConference in Computer Vision and Pattern Recognition (CVPR), 2016 -
Deep Convolutional Feature Point Descriptors

We learn compact discriminative feature point descriptors using a convolutional neural network. We directly optimize for using L2 distance by training with a pair of corresponding and non-corresponding patches correspond to small and large distances respectively using a Siamese architecture. We deal with the large number of potential pairs with the combination of a stochastic sampling of the training set and an aggressive mining strategy biased towards patches that are hard to classify. The resulting descriptor is 128 dimensions that can be used as a drop-in replacement for any task involving SIFT. We show that this descriptor generalizes well to various datasets.
Discriminative Learning of Deep Convolutional Feature Point DescriptorsEdgar Simo-Serra*, Eduard Trulls*, Luis Ferraz, Iasonas Kokkinos, Pascal Fua, Francesc Moreno-Noguer (* equal contribution)International Conference on Computer Vision (ICCV), 2015 -
Neuroaesthetics in Fashion
Being able to understand and model fashion can have a great impact in everyday life. From choosing your outfit in the morning to picking your best picture for your social network profile, we make fashion decisions on a daily basis that can have impact on our lives. As not everyone has access to a fashion expert to give advice on the current trends and what picture looks best, we have been working on developing systems that are able to automatically learn about fashion and provide useful recommendations to users. In this work we focus on building models that are able to discover and understand fashion. For this purpose we have created the Fashion144k dataset, consisting of 144,169 user posts with images and their associated metadata. We exploit the votes given to each post by different users to obtain measure of fashionability, that is, how fashionable the user and their outfit is in the image. We propose the challenging task of identifying the fashionability of the posts and present an approach that by combining many different sources of information, is not only able to predict fashionability, but it is also able to give fashion advice to the users.
Neuroaesthetics in Fashion: Modeling the Perception of FashionabilityEdgar Simo-Serra, Sanja Fidler, Francesc Moreno-Noguer, Raquel UrtasunConference in Computer Vision and Pattern Recognition (CVPR), 2015 -
Monocular Single Image 3D Human Pose Estimation

This line of research focuses on the estimation of the 3D pose of humans from single monocular images. This is an extremely difficult problem due to the large number of ambiguities that rise from the projection of 3D objects to the image plane. We consider image evidence derived from the usage of different detectors for the different parts of the body, which results in noisy 2D estimations where the estimation uncertainty must be compensation. In order to deal with these issues, we propose different approaches using discriminative and generative models to enforce learnt anthropomorphism constraints. We show that by exploiting prior knowledge of human kinematics it is possible to overcome these ambiguities and obtain good pose estimation performance.
ProjFlow: Projection Sampling with Flow Matching for Zero‑Shot Exact Spatial Motion ControlAkihisa Watanabe, Qing Yu, Edgar Simo-Serra, Kent FujiwaraConference in Computer Vision and Pattern Recognition (CVPR), 2026A Joint Model for 2D and 3D Pose Estimation from a Single ImageEdgar Simo-Serra, Ariadna Quattoni, Carme Torras, Francesc Moreno-NoguerConference in Computer Vision and Pattern Recognition (CVPR), 2013Single Image 3D Human Pose Estimation from Noisy ObservationsEdgar Simo-Serra, Arnau Ramisa, Guillem Alenyà, Carme Torras, Francesc Moreno-NoguerConference in Computer Vision and Pattern Recognition (CVPR), 2012 -
Geodesic Finite Mixture Models

There are many cases in which data is found to be distributed on a Riemannian manifold. In these cases, Euclidean metrics are not applicable and one needs to resort to geodesic distances consistent with the manifold geometry. For this purpose, we draw inspiration on a variant of the expectation-maximization algorithm, that uses a minimum message length criterion to automatically estimate the optimal number of components from multivariate data lying on an Euclidean space. In order to use this approach on Riemannian manifolds, we propose a formulation in which each component is defined on a different tangent space, thus avoiding the problems associated with the loss of accuracy produced when linearizing the manifold with a single tangent space. Our approach can be applied to any type of manifold for which it is possible to estimate its tangent space.
3D Human Pose Tracking Priors using Geodesic Mixture ModelsEdgar Simo-Serra, Carme Torras, Francesc Moreno-NoguerInternational Journal of Computer Vision (IJCV) 122(2):388-408, 2016Lie Algebra-Based Kinematic Prior for 3D Human Pose TrackingEdgar Simo-Serra, Carme Torras, Francesc Moreno-NoguerInternational Conference on Machine Vision Applications (MVA) [best paper], 2015Geodesic Finite Mixture ModelsEdgar Simo-Serra, Carme Torras, Francesc Moreno-NoguerBritish Machine Vision Conference (BMVC), 2014 -
Deformation and Light Invariant Descriptor

DaLI descriptors are local image patch representations that have been shown to be robust to deformation and strong illumination changes. These descriptors are constructed by treating the image patch as a 3D surface and then simulating the diffusion of heat along the surface for different intervals of time. Small time intervals represent local deformation properties while large time intervals represent global deformation properties. Additionally, by performing a logarithmic sampling and then a Fast Fourier Transform, it is possible to obtain robustness against non-linear illumination changes. We have created the first feature point dataset that focuses on deformation and illumination changes of real world objects in order to perform evaluation, where we show the DaLI descriptors outperform all the widely used descriptors.
DaLI: Deformation and Light Invariant DescriptorEdgar Simo-Serra, Carme Torras, Francesc Moreno-NoguerInternational Journal of Computer Vision (IJCV) 115(2):135-154, 2015Deformation and Illumination Invariant Feature Point DescriptorFrancesc Moreno-NoguerConference in Computer Vision and Pattern Recognition (CVPR), 2011 -
Clothes Segmentation

In this research we focus on the semantic segmentation of clothings from still images. This is a very complex task due to the large number of classes where intra-class variability can be larger than inter-class variability. We propose a Conditional Random Field (CRF) model that is able to leverage many different image features to obtain state-of-the-art performance on the challenging Fashionista dataset.
A High Performance CRF Model for Clothes ParsingEdgar Simo-Serra, Sanja Fidler, Francesc Moreno-Noguer, Raquel UrtasunAsian Conference on Computer Vision (ACCV), 2014 -
Kinematic Synthesis of Tree Topologies

Kinematic synthesis consists of the theoretical design of robots to comply with a given task. In this project we focus on finite point kinematic synthesis, that is, given a specific robotic topology and a task defined by spatial positions, we design a robot with that topology that complies with the task.
Tree topologies consist of loop-free structures where there can be many end-effectors. A characteristic of these topologies is that there are many shared joints. This allows some structures that may seem redundant to not actually be redundant when considering all the end-effectors at once. The main focus of this work is the design of grippers that have topologies similar to that of the human hand, which can be seen as a tree topology.
Kinematic Synthesis using Tree TopologiesEdgar Simo-Serra, Alba Perez-GraciaMechanism and Machine Theory (MAMT) 72:94-113, 2014Kinematic Synthesis of Multi-Fingered Robotic Hands for Finite and Infinitesimal TasksEdgar Simo-Serra, Alba Perez-Gracia, Hyosang Moon, Nina RobsonAdvances in Robot Kinematics (ARK), 2012Design of Non-Anthropomorphic Robotic Hands for Anthropomorphic TasksEdgar Simo-Serra, Francesc Moreno-Noguer, Alba Perez-GraciaASME International Design Engineering Technical Conferences (IDETC), 2011Kinematic Model of the Hand using Computer VisionEdgar Simo-SerraDegree Thesis, 2011