Overview
Below we present some additional results and insights on the approaches we propose. The additional results correspond to the CVPR 2013 approach in which we present a joint model for both 2D and 3D pose estimation. In all cases we always work with a single monocular image as input.
The CVPR 2013 approach consists of the combination of a strong 3D generative model with a bank of 2D part detectors. This can be derived from the probabilistic formulation used by pictorial structures, in which the following equation can be obtained:
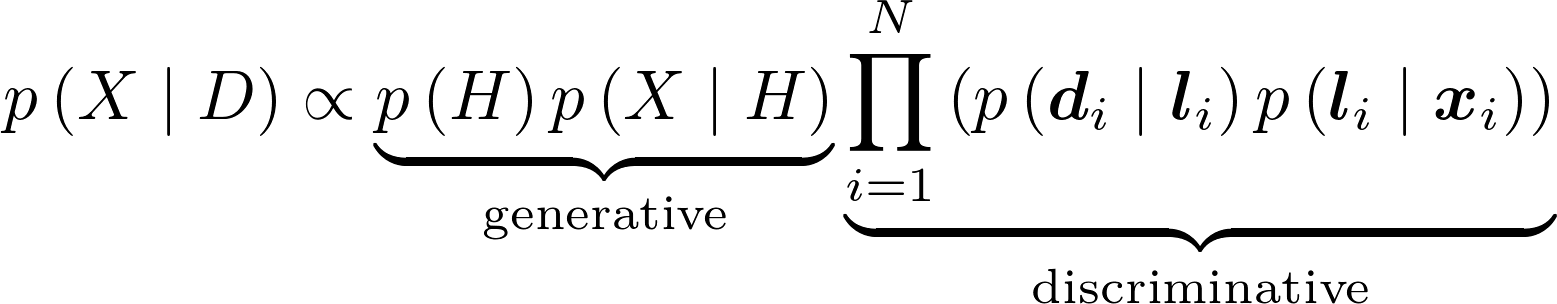
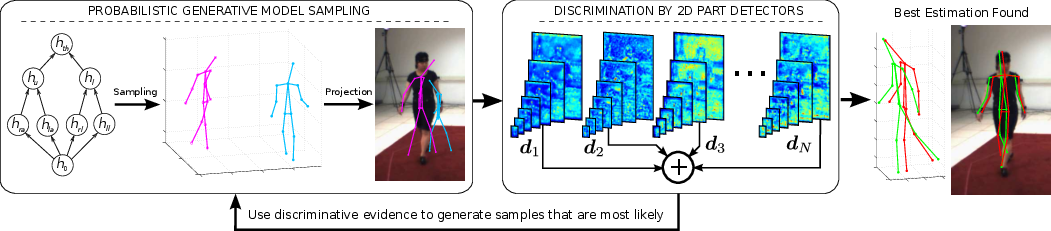
where X is the 3D pose, L is the 2D pose, H is a set of latent variables and D is the image evidence. We can see that two clear components can be distinguished, corresponding to the generative model and discriminative detectors respectively. A visual overview of the approach can be seen below.
Annotation Divergence
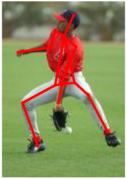
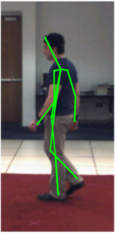
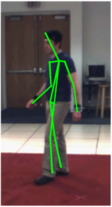
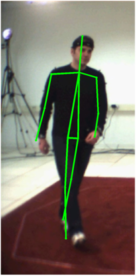
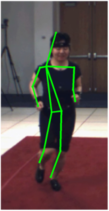
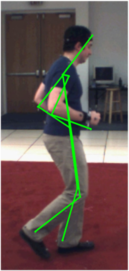
We evaluate the differences between the 2D annotations and the 3D annotations. The 2D annotations on the PARSE dataset were manually done by different persons. On the other hand, the HumanEva dataset obtains the 3D annotations by using an automatic system that depends on markers. Thus the placement of the markers becomes crucial and divergences may occur between the two datasets. A simple example is the head, while the 2D annotations are able to mark the center of the head, the 3D annotations use a marker located on the forehead. As explained in the paper, we compensate this kind of divergences by learning the relative weighting of the parts. Below we illustrate these differences in the annotations and show examples from both datasets, which are especially noticeable in lateral views.
PARSE Dataset







HumanEva Dataset






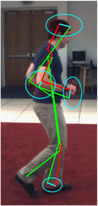 |
We highlight some of the differences on the left. These differences are primarily caused by the markers used to obtain the 3D ground truth. These markers are external to the human body, while the 2D annotations on the PARSE dataset are done on the actual body parts. The ground truth is marked in green, the few parts with large differences from the ground truth are marked in red and the differences are marked in cyan. |
TUD Stadmitte
We have evaluated qualitatively on the TUD Stadmitte sequence as there is no available ground truth. This is a short yet extremely challenging sequence due to various factors. First it is a complex outdoor scene with lots of occlusions of different pedestrians. Additionally the pedestrians generally have uniform jackets and keep their hands in their pockets. This makes it very difficult for the upper body part detectors to provide meaningful responses. Finally, for algorithms that have been trained on the 3D walking sequence of the HumanEva dataset, it provides yet another challenge as real world pedestrians generally have very different walking kinematics from those obtained in laboratory conditions using a small circular track.
As done with the HumanEva dataset, we use the 2D annotations to crop the image to each individual and use that for the input of our algorithm. However, unlike the HumanEva dataset, we have no 3D information at all and must perform the coarse initialization shown in our paper. In addition, the annotations on the sequence do not take into account occlusions, either by borders or by other pedestrians. We perform no additional filtering on these annotations and try to evaluate our method on all the frames.
For a qualitative comparison with a tracking method (remind that we do not consider temporal consistency and estimate 3D and 2D from one single frame), please see this project site. It is interesting to note that many of the issues we face, such as poor results of the upper body detector, are shared with the original results on the sequence. However, as they use tracking, they are able to correct them with additional temporal information.
Below we show 5 selected frames from the sequence with comments on the results.

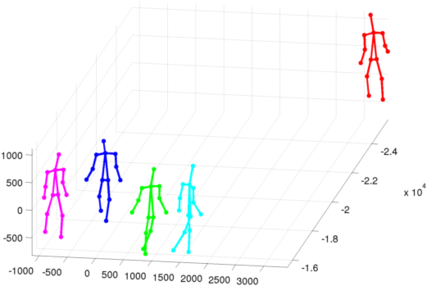
Frame 7024:The man on the right is too close to the border such that detectors fail to properly estimate half of his body.

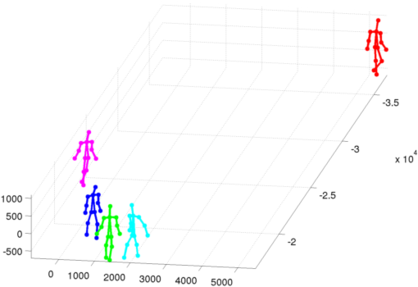
Frame 7047:Man in cyan is sharing leg detection with a pedestrian he is occluding. Person in red is still too close to the border. Additionally, the man in purple is partially occluded by a small tree and is improperly located.

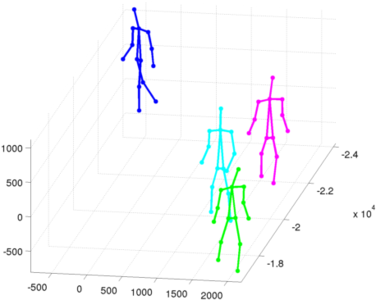
Frame 7074:All but the man in green are partially occluded. In the case of the man in green, the upper body detectors fail to give meaningful output and he is erroneously detected as facing forwards. As we can see, due to the overall weakness of the upper body detectors to precisely detect parts when pedestrians have hands in their pockets has a tendency to give us 90 degree errors in viewpoints.

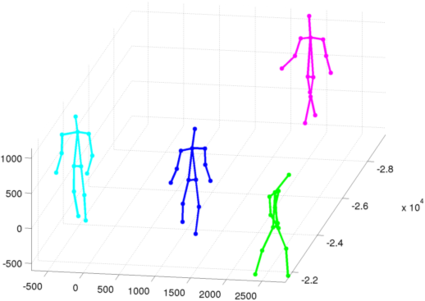
Frame 7111:Only one person is annotated due to the heavy occlusion of two pedestrians, which we improperly detect as the green person.

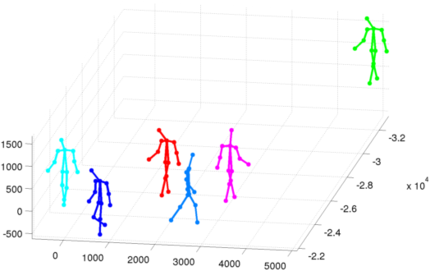
Frame 7129:Person in green is too close to the border and improperly detected at lower scale (further away). There is an occlusion of the person in light blue on the person in purple.

