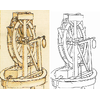
イラストの研究
線画やラフスケッチのイラストはスパースだけではなく、色々な画風があるため、イラストの画像処理が困難である。さらに、精密な出力は求められているので、小さい間違いでも致命的である。本研究は反復作業を証言し、イラストレーターの応援することを目指す。
-
Smart Inker: ラフスケッチのペン入れ支援

本研究では、深層学習を応用して対話的にラフスケッチのペン入れができるツール、スマートインカー(Smart Inker)を提案する。 スマートインカーは、途切れた線を自然につなぎ、不要な線を効率的に消すことが可能な“スマート”ツール機能をもち、自動出力された線画を効果的に修正することができる。 このような機能を実現するため、本手法ではデータ駆動型のアプローチを取る。スマートインカーは全層畳み込みニューラルネットワークにもとづいており、 このネットワークはユーザ編集とラフスケッチ両方を入力とし正確な線画を出力できるように学習させている。 これにより、様々な種類の複雑なラフスケッチに対して高精度かつリアルタイムの編集が可能となる。 これらのツールの学習のため、提案手法では2つの重要な技術を考案する。すなわち、ユーザ編集をシミュレーションして学習データを作成するデータ拡張手法、 および線画のベクタデータにより学習した細線化ネットワークを用いた線画標準化手法である。これらの手法とスケッチに特化したデータ拡張を組み合わせることで、 実際のユーザ編集データを用意することなく様々な編集パターンを含む学習データを大量に作成でき、効果的にそれぞれのネットワークを学習させることができる。 実際に提案ツールを用いてラフスケッチにペン入れをするユーザテストを行った結果、商用のイラスト制作ソフトに比べ提案ツールは簡単かつ短時間で線画作成が可能となり、 イラスト作成経験がほとんどないユーザでもきれいな線画を作成できることが確かめられた。
-
敵対的データ拡張による自動線画化
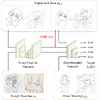
本研究では、ラフスケッチの自動線画化を効果的に学習するための統合的なフレームワークを提案する。提案手法では、線画化ネットワークおよび線画識別ネットワークを構築し、線画識別ネットワークは本物の線画と線画化ネットワークによって作られた線画を区別するように、線画化ネットワークは出力した線画を識別ネットワークが区別できないように学習を行う。このアプローチには2つの利点がある。一つ目は、識別ネットワークは線画の「構造」を学習できるため、線画化ネットワークがより精細で本物に近い線画を出力できるようになる。二つ目は、対応関係のないラフスケッチと線画を学習に取り入れることができ、実世界の多様な教師なしデータを線画化ネットワークに学習させることができる点である。本学習フレームワークを用いることで、最新の線画化手法よりも精細で多様な線画化が可能となる。さらに、提案手法は入力画像のみをさらに学習することで、入力画像に対する線画化ネットワークの最適化を行うことができる。また、提案手法により、逆問題、すなわち線画から鉛筆画への変換も学習できることを示す。
-
ラフスケッチの自動線画化

本研究では、畳込みニューラルネットワークを用いてラフスケッチを線画に自動変換する手法を提案する。既存のスケッチ簡略化手法の多くは単純なラフスケッチのベクター画像のみを対象としており、スキャンした鉛筆画など、ラスター形式の複雑なラフスケッチを線画化するのは困難であった。これに対し提案手法では、3種類の畳込み層から構成されるニューラルネットワークモデルによって複雑なラフと線画の対応を学習することで、ラスター形式の様々なラフスケッチを良好に線画化することができる。提案モデルでは、任意のサイズやアスペクト比をもつ画像を入力として扱うことが可能であり、出力される線画は入力画像と同じサイズになる。また、このような多層構造をもつモデルを学習させるため、ラフスケッチと線画がペアになった新しいデータセットを構築し、モデルを効果的に学習させる方法を提案した。得られた結果についてユーザテストを行い、提案手法の性能が既存手法を大きく超えることを確認した。
論文

@Article{MadonoPG2023,
author = {Koki Madono and Edgar Simo-Serra},
title = {{Data-Driven Ink Painting Brushstroke Rendering}},
journal = {Computer Graphics Forum (Pacific Graphics)},
year = 2023,
}
@InProceedings{CarrilloCVPRW2023,
author = {Hernan Carrillo and Micha\"el Cl/'ement and Aur\'elie Bugeau and Edgar Simo-Serra},
title = {{Diffusart: Enhancing Line Art Colorization with Conditional Diffusion Models}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2023,
}

@Article{HuangCVM2023,
title = {{Controllable Multi-domain Semantic Artwork Synthesis}},
author = {Yuantian Huang and Satoshi Iizuka and Edgar Simo-Serra and Kazuhiro Fukui},
journal = "Computational Visual Media",
year = 2023,
volume = 39,
number = 2,
}
@Article{HaoranSIGGRAPH2021,
author = {Haoran Mo and Edgar Simo-Serra and Chengying Gao and Changqing Zou and Ruomei Wang},
title = {{General Virtual Sketching Framework for Vector Line Art}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2021,
volume = 40,
number = 4,
}

@InProceedings{ZhangCVPR2021,
author = {Lvmin Zhang and Chengze Li and Edgar Simo-Serra and Yi Ji and Tien-Tsin Wong and Chunping Liu},
title = {{User-Guided Line Art Flat Filling with Split Filling Mechanism}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2021,
}
@InProceedings{YuanCVPRW2021,
author = {Mingcheng Yuan and Edgar Simo-Serra},
title = {{Line Art Colorization with Concatenated Spatial Attention}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)",
year = 2021,
}

Our algorithm is content-aware, with generated lighting effects naturally adapting to image structures, and can be used as an interactive tool to simplify current labor-intensive workflows for generating lighting effects for digital and matte paintings. In addition, our algorithm can also produce usable lighting effects for photographs or 3D rendered images. We evaluate our approach with both an in-depth qualitative and a quantitative analysis which includes a perceptual user study. Results show that our proposed approach is not only able to produce favorable lighting effects with respect to existing approaches, but also that it is able to significantly reduce the needed interaction time.
@Article{ZhangTOG2020,
author = {Lvmin Zhang and Edgar Simo-Serra and Yi Ji and Chunping Liu},
title = {{Generating Digital Painting Lighting Effects via RGB-space Geometry}},
journal = "Transactions on Graphics (Presented at SIGGRAPH)",
year = 2020,
volume = 39,
number = 2,
}

@Article{SimoSerraSIGGRAPH2018,
author = {Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Real-Time Data-Driven Interactive Rough Sketch Inking}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2018,
volume = 37,
number = 4,
}
@Article{SasakiCGI2018,
author = {Sasaki Kazuma and Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa}},
title = {{Learning to Restore Deteriorated Line Drawing}},
journal = "The Visual Computer (Proc. of Computer Graphics International)",
year = {2018},
volume = {34},
pages = {1077--1085},
}

@Article{SimoSerraTOG2018,
author = {Edgar Simo-Serra and Satoshi Iizuka and Hiroshi Ishikawa},
title = {{Mastering Sketching: Adversarial Augmentation for Structured Prediction}},
journal = "Transactions on Graphics (Presented at SIGGRAPH)",
year = 2018,
volume = 37,
number = 1,
}
@InProceedings{SasakiCVPR2017,
author = {Kazuma Sasaki Satoshi Iizuka and Edgar Simo-Serra and Hiroshi Ishikawa},
title = {{Joint Gap Detection and Inpainting of Line Drawings}},
booktitle = "Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)",
year = 2017,
}

@Article{SimoSerraSIGGRAPH2016,
author = {Edgar Simo-Serra and Satoshi Iizuka and Kazuma Sasaki and Hiroshi Ishikawa},
title = {{Learning to Simplify: Fully Convolutional Networks for Rough Sketch Cleanup}},
journal = "ACM Transactions on Graphics (SIGGRAPH)",
year = 2016,
volume = 35,
number = 4,
}
ソフトウェア